摘要
分布式系统中的一致性问题是比较有效的解决服务不可靠的途径,它可以使分布式节点形成一个相互协调的系统并对外提供一致的服务。而复制状态机一般作为一致性算法的实现手段,其会产生相同的执行副本复制给所有节点执行,直至所有节点最终状态达成一致。通常一致性算法主要考虑的一个问题就是容错,即任意多个节点发生故障,整个系统依然能对外提供一致的服务。Raft是一个比较著名的一致性算法,但它为了可理解性的设计使得性能方面不得不做出权衡。本文针对Raft做深入研究,主要工作如下:1. 针对传统Raft在较大并发场景下存在的性能问题做出改进,在其基础之上引入Pre-Proposal阶段,通过批处理的异步日志复制和异步刷盘来实现性能上的提升。最后的实验证明了改进后的Raft算法能提升2-3.6倍以上的系统吞吐量,对于并行请求的处理效率能提升20%以上。2. 基于简洁易用的系统设计,实现Raft,将Raft抽象成一个共识模块并对外提供状态机接口以便适应不同种类的业务场景。状态机接口与上层业务层和下层存储层设计上均解耦合。通过构建基于共识模块之上的分布式存储模型,给分布式存储服务提供基本思路。 3. 通过模拟一些网络分区的场景验证系统的正确性,最终实验的结论也达到了预期。
关键词: 分布式系统、一致性算法、共识算法、Paxos、Raft
Abstract
The consistency problem in distributed system is an effective way to solve the problem of unreliable services. It can make distributed nodes form a coordinated system and provide consistent services. Replication state machine is generally used as a means of consistency algorithm, which will produce the same execution copy to all nodes until the final state of all nodes is agreed. Generally, one of the main considerations of consistency algorithm is fault tolerance, that is, if any number of nodes fail, the whole system can still provide consistent services. Raft is a well-known consistency algorithm, but it has to make trade-offs in terms of performance for the sake of comprehensible design. The main work of this paper is as follows: 1) Aiming at the performance problems of traditional raft in large concurrency scenarios, the pre-proposal phase is introduced to improve the performance by batch asynchronous log replication and asynchronous disk brushing. Finally, the experimental results show that the improved raft algorithm can improve the system throughput by more than 2-3.6 times, and the processing efficiency of parallel requests can be improved by more than 20%. 2) Based on the simple and easy-to-use system design, raft is implemented. Raft is abstracted as a consensus module and state machine interface is provided to adapt to different kinds of business scenarios. The state machine interface is decoupled from the upper business layer and the lower storage layer. By building a distributed storage model based on consensus module, the basic idea of distributed storage service is provided. 3) The correctness of the system is verified by simulating some network partition scenarios, and the final experimental conclusion also achieves the expected results.
Keywords: Distributed system,Consensus algorithm,Consistency algorithm,Paxos,Raft
1. 绪论
1.1 研究背景及意义
随着互联网技术的发展,全球数据总量指数级增长。据估算,在2005年全球数据量只有5PB,而2021年达到了60ZB(60万亿GB),估算2025年全球数据量总将会超过90ZB。对于互联网的这种增长趋势,传统单机系统虽然迭代的也很快,但其存储能力无法达到相同量级的增长速度。根据摩尔定律,单位时间内待处理的性能指数越高,付出的金钱会越多,性价比越低,所以仅使用计算机硬件而不升级软件终会产生瓶颈。目前针对如此规模数据量体系下的数据处理,分布式系统是一个较好的选择。
为了应对不断增长的海量用户和更大规模的并发挑战,理想条件下,企业追求更加弹性的业务扩展性和吞吐量,可以通过购买更多的机器以处理更高的负载实现对当前业务系统横向扩充,但由此服务器会宕机和产生故障是不可避免的。在当代大规模业务系统下每年磁盘损坏率达到了0.88%[1],服务器也经常宕机[2],每天都会发生网络分区[3-5]。各种普通硬件、驱动器、服务器硬件在操作系统中产生错误都有可能导致网络中的消息乱序、丢包和延迟,虽然有一系列相关协议保证其正确性,但性能上依然会有不小的损失。
在追求横向拓展的同时,分布更多的节点意味着会面临更大的故障概率和风险。而作为服务提供方,需要向用户端隐藏错误,即部分节点故障仍能提供正确和可用的服务。于是需要分布式服务能自动处理服务器的崩溃和恢复,这对分布式系统来说是一个挑战。
在本文讨论具体的分布式容错之前,需要针对故障模型有一个比较明确的约束范围。因为容错也需要特定的场景对系统组件的错误行为做出一个范围假设。其中拜占庭故障[6](Byzantine)和错停故障[7](Fail-Stop)是分布式系统中较为常见的两种故障模型:
(1) 拜占庭故障
拜占庭故障是故障中最难接受的故障种类。节点可以不受协议限制做任何操作,比如不一致的响应、对不同的提议乱投票、不同的故障节点联合起来影响正确的节点,会破坏分布式系统所规定的安全性。通常,我们认为当发生拜占庭故障时,整个系统已经达到了难以挽回的程度。
(2) 错停故障
该模型假设的是,如果一个节点出错,这个节点将会停止运行,且其他所有节点能同步感知到错误的发生。
基于拜占庭故障的模型是最悲观的模型,但这种故障很少会发生,它只能作为我们讨论故障模型的一个上界(即不会有比这更难接受的模型)。与之相反,错停模型作为我们讨论故障模型的下界,因为有一致性协议的存在,除了物理因素导致宕机、重启外,很少有节点发生错误就立刻停止运行。在错停故障下,复制状态机常被用于解决该条件下的各种容错问题[8]。由一部分服务器上的本地状态机产生状态相同的执行副本,通过网络协议发送给其他服务器,这样即便在部分机器错停的情况下状态机也能继续执行。一个比较典型的应用就是使用由领导人节点管理的状态机负责处理副本的执行和发送,这样可以确保节点宕机的情况下集群也能对外存活。一些较为成熟的系统,如Zookeeper[9]、TiKV[10]和Chubby[11]等都基于此实现。
一致性问题通常解决的是多个服务节点之间的状态如何达成一致。由于网络原因,系统通常会出现各种问题:如宕机、网络抖动等。故障发生会使得服务变得不可靠。为了解决这个问题,产生了一致性算法。一致性算法在分布式数据库[12-14]、区块链技术[15-16]、高性能中间件[17]等领域都有良好的应用,也是实现这些系统的基础。
本文研究的分布式系统中较为基础的分布式共识协议及一致性问题,通过实现满足线性一致性语义的共识算法,提出一种基于共识协议实现并具有容错能力的分布式存储模型,为分布式存储服务提供了一套解决方案。
1.2 国内外研究现状
分布式共识算法里,有一个比较著名的算法是Paxos[18]。在过去,Leslie Lamport的Paxos算法在过去一直是一致性算法的标杆,许多大型分布式系统都构建于Paxos之上[11]。该算法具有强一致性和高度容错性,大多数共识协议都基于此算法扩充或受到影响。
Paxos论文中详细的定义了能在单决策达成一致的方法,比如日志复制中的单个条目,一次单决策子集也被称为Basic-Paxos。将连续多个Basic-Paxos实例组合起来得到一个多决策实例(Mutil-Paxos)。
但它有2个很明显的问题:一是算法晦涩难懂,非常让人难以理解。即便出现简化的版本试图让其他人更加容易解释它,但想要理解Paxos依然很具有挑战性。这一难点主要来自于Paxos选择使用单决策的子集组合作为基础展开,对于多决策组合后的算法,是非常微妙的,无法通过直观的解释证明其他部分场景下也正确。二是Paxos论文中缺乏对多决策Paxos实施的细节,这导致每一种基于Paxos研究的现实系统都开发出了明显不一样的版本,系统的正确性验证需要花费大量的努力且结果存疑。
其它比较有名的算法有Gossip[19]、ViewStamped Replcation[20]和Zab[21]。其中
ViewStamped Replcation算法最初是作为数据库中的一部分提出,之后又以独立论文发表;Gossip算法是基于流行病传播方式的节点或者进程之间信息交换的协议,在Cassandra[22]中得到应用;Zab协议是构建分布式协调系统Zookeeper[9]的核心算法,是一种用于支持崩溃恢复的原子广播协议。
分布式协议是复杂的,由此Raft[23]协议诞生,它补充了多决策Paxos的细节,强调了可理解性,将一致性问题分解成几个连续的子问题,最后通过安全性保证系统正确。Raft算法足够完整,可以为构建实际系统所面临的各种问题提供解决方案,在部署上性能也和Paxos相差无几。Raft在工业领域得到了极大的关注,目前很多开源项目都选择使用Raft作为其共识模块。
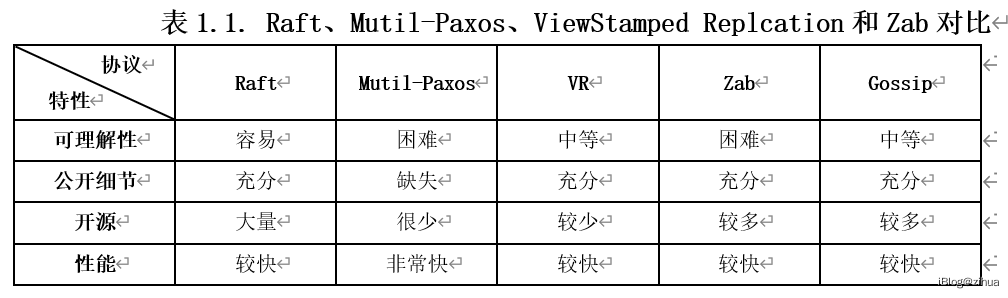
总结以上分析,表1.1给出Raft、Mutil-Paxos、ViewStamped Replication和Zab的对比。对比中可以看出Raft相较于其他共识协议有不错的适应性,更加适合工业场景的实现。
由于大数据行业的兴起,国内出现了大量基于共识算法构建的大型分布式系统软件。PingCAP实现了Raft的诸多细节并做了很多优化工作,他们的开源分布式数据库TiDB[24]也基于Raft构建,已应用在游戏、金融、互联网等诸多领域,并与国内外大型互联网企业建立合作。蚂蚁金服基于Paxos实现的OceanBase[25],支撑了淘宝近10年来双11流量,2019年高峰期能达到6100W QPS。腾讯集团微信团队基于Paxos做的C++库PhxPaxos[26]用于微信的生产环境中,主要实现微信聊天记录备份。
以共识算法为基础实现系统的需求会越来越多,以容错为基础构建更高效的共识算法是一个比较不错的研究方向。以理解性为目标设计的共识协议Raft是一个值得研究的对象,TiDB和PolarFS的例子告诉我们,Raft在性能方面还具有非常大的潜力,为此本文针对Raft协议开展研究工作。
1.3 本文工作
本文重点研究分布式系统中最为核心和基础的共识协议和一致性问题,从后续可拓展性、工程可维护性角度考虑,经过广泛比较分析,最终选择Raft协议作为理论依据。针对非拜占庭故障模型下,致力于实现一个强一致的、高度容错并满足线性一致语义的Key-Value存储模型,为此提供一套完整的解决方案。
当确定选用Raft作为共识模块核心算法之后,本文对Raft官网提供的实现列表[27]进行分析和研究,发现大部分虽然也实现了Raft,但基本都属于实验性质半成品。要么功能性实现不完整,要么程序存在问题无法验证其正确。完整实现的有Etcd[28]、TiKV[29]、RethinkDB[30]等,但他们都是商业级实现,Raft只是作为其一小部分,并没有抽象成基础库的形式,耦合度较高,对阅读和理解造成了阻碍。
由此需要一个简洁和清晰的Raft实现作为核心组件,接口足够简单,能屏蔽Raft本身的很多细节,业务层只需要使用接口即可实现完整的分布式系统。这些细节也是实现理解Raft本身最为核心的一个部分。
基于以上的考虑,本文根据需求使用Java语言构建了一个简洁易用的Raft库实现。该实现具有清晰的内部交互逻辑,易用的状态机接口,以及能保证程序的正确性和可靠运行。并针对传统Raft协议在较大并发场景下存在的性能问题做出改进,通过引入Pre-Proposal阶段,使用批处理的异步日志复制和异步刷盘来实现并行效率上的优化。构建的系统最终能满足Key-Value的线性语义和故障容错。具体的,本文贡献如下:
- 整理分布式一致性算法问题相关成果和研究方法,针对非拜占庭故障场景并使用复制状态机模型,分析分布式一致性技术的定义及细节。
- 横向对比其他共识协议,基于高扩展性和可理解性的需求选择构建Raft协议为基础,保证实现的Raft能满足各种复杂故障场景的可用性。
- 以高效可靠为目标构建Raft,实现一个具有容错能力的分布式Key-Value存储系统,并完善系统与客户端的交互行为。并在业务层对Raft算法进行优化,使其吞吐性能明显高于传统Raft算法2-3.6倍以上。
- 进一步对系统正确性和不同故障场景进行充分测试,针对可用性、正确性和一致性设定补充一些场景做验证。
本文相关研究贡献发表至国际学术会议2021 7th Annual International Conference on Computer Science and Applications,目前已被接收。
1.4 本文章节安排
本文使用Raft共识算法针对分布式一致性问题做研究,实现Raft协议的分布式系统,并对算法在部分场景做出优化以获得更高的性能。本文章节安排如下:
- 第一章 绪论。本章主要介绍共识算法的国内外研究现状和本文组织结构。
- 第二章 分布式共识算法相关研究。本章介绍了分布式系统相关基本定理,比如CAP、Quorum和Paxos,以这些为基础,为后续Raft的研究提供理论依据。
- 第三章 Raft实现。本章介绍实现Raft的关键技术,包括复制状态机、领导人选举和日志复制。
- 第四章 改进的Raft算法及分布式存储模型。本章基于实现的Raft算法,针对Raft算法在并发场景下的性能问题提出优化方案,以及基于Raft算法构建具有完整功能的分布式存储系统。
- 第五章 性能测试与分析。本章针对第四章的内容,构建测试环境,针对网络分区和并发场景下做出测试,最后通过结论证明系统的正确性。
- 第六章 全文总结。总结文章工作以及对后续工作的展望,指明后续工作的主要方向。
2. 分布式共识算法研究
2.1 概述
分布式系统区别于传统单机系统,总的来说,分布式系统要做的任务就是把多台机器结合协同完成一项工作,可以是计算工作,可以是存储相关工作,为此便多出了诸如分布式计算、分布式存储等方向。目前,一些比较典型的应用有适用于实时分析OLAP场景的分析性数据库[31]、分布式存储HDFS[32]、分布式计算Spark[33]等都是系统应用中的实例。分布式系统通常具有很大规模,就现代数据中心来说,其机器数目以万计。如此规模之下,每天产生诸如网络分区、链路故障、机房停电、硬盘损坏、机房着火等等一系列问题。为了让数据不轻易丢失,通过异地保存多副本冗余做容错的方式可以解决问题。即便一处停机,也可以重新启用另外一处继续提供服务。
但由此伴随而来的是如何对数据如何保持一致性,即便数据能够复制产生冗余,但何时发生复制行为?是增量复制还是全量复制?这都是需要深入探讨的问题。近十年来,从标志性的Paxos开始,诞生了很多优秀的一致性算法,但与分布式一致性相关的算法不仅实现困难且正确性得不到保证,为此,类似于Raft这种有详细的论文和数据支撑一致性算法得到了广泛的关注和支持。本章主要研究分布式算法有关概论,并与Raft做比较。
2.2 相关定理
2.2.1 CAP定理
CAP定理[34]是讨论分布式模型关系的代表理论,C为consistency,一致性;A为availability,可用性;P为partition-tolerance,分区容错性。CAP理论告诉我们,任何场景下一致性、可用性和分区容错性无法同时全部满足。它基于以下事实:由于不存在完美的网络环境,网络始终会有延迟,且延迟远远大于本地程序交互,如果需要保证服务可用,必然会分布多数据副本,在网络延迟下就会带来数据不一致的问题;在多副本的环境下,想保证每份数据副本一致,那么对操作延迟势必会有一定要求,显然如今的网络环境的延迟和稳定性并不满足。
分区容错能力是构建分布式系统的基础,如果放弃分区容错性那么也代表放弃了构建分布式系统这一目标,而根据系统选择的可用性或者一致性,我们可以把具体的系统分为强一致和最终一致,这也代表了我们构建系统的目标。
在Raft中,是否是强一致取决于领导人节点的实现,如果我们规定一次Proposal必须被多数派节点接受后才能被提交,那么客户端的读请求最终读到的是最新版本的数据,此时客户端视角下是一致的。在此基础之上稍加改变,当任意节点接受到Proposal后立即提交,然后异步将日志副本复制给其他节点提交,此时客户端的读请求不一定能读到最新的数据,但能保证的是,在某个时间点内,集群中大多数节点均会提交该日志,则此时的读会是一致的读。
2.2.2 Quorum、WARO和Majority
Quorum[35]是一种通用的用于确保数据间一致性和可用性的机制,这是一种在读和写之间的权衡机制。在Quorum机制下,当某次写操作成功在N个副本中的W写入,则该更新成功,令R>N-W,则最多连续读取R个副本,必定能读到最新的数据副本。Quorum集合的形式化定义如下:
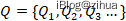
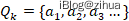
其中Q表示Quorum的集合,a_k可以归纳为集群节点的子集。当接受写的节点满足任意的Q_k时,此时对集群发起的读则是一致性读。比如,集群节点N={a,b,c},则Q={{a,b},{a,c},{b,c},{a,b,c},,,},如果此时向子集写如成功,那么最多读2个副本一定能读到包含最新数据的a。
WARO(Write-all-read-one)是一种比较极端的Quorum,在Quorum中,如果W=N,则读任一副本均能读到最新的数据。从定义上看,WARO牺牲了写操作的可用性,增强了读操作的可用性,写操作只要有一个副本更新失败,本次操作均视为失败,而读操作没有限制。
Majority称为多数派,也是一种特殊的Quorum机制。即当多于半数的写(W≥[N⁄2]+1)才算成功,例如5节点模型中,3个节点成功写入副本,则最多读3个节点也能读到最新副本。Raft并没有选择比较极端的WARO,而是使用Majority作为其实现一致性读写的基础。
2.3 Paxos
在过去,Paxos一直是大多数实现一致性算法的一个标准。Google Chubby的作者Mike Burrow对Paxos认为世界上只有一种一致性算法,那就是Paxos,其他算法都是基于Paxos的衍生或变种。Paxos论文中描述了Basic-Paxos算法并给出了详细的形式化验证,提出了Mutil-Paxos思想,但缺少实现细节。
Paxos角色主要分为提议者(Proposer),学习者(Learner)和决策者(Acceptor):
- 提议者(Proposer),负责提出提案,包括提案编号(Proposal ID)的产生与参与提议的值(Proposal Value)。
- 决策者(Acceptor),参与到决策中,负责处理Proposer的提交的提案,如果提案满足被成功接收的条件(accept),则会广播到其他Acceptor节点,当该提案形成多数派时,则该提案状态为批准。
- 学习者(Learner),不参与决策。可以看作执行器,当一个提案被多数派批准后,Learner会做出对应的处理,比如复制日志、执行业务等。Learner角色允许多个。
一次完整的Paxos决策流程(图2.1)分为2个阶段。准备阶段(Prepose)和接收阶段(Accept)。准备阶段,获取一个新提案的提案号,之后向所有Acceptors广播Prepare(n)请求,Acceptor收到该议案后,如果提案满足被提交的条件,Acceptor就会对其做出承诺,即不会再接受提案编号比当前提案编号更小的提案。在接受阶段,当提案被大多数的Acceptors所接受时,形成多数派的Quorum,并向Proposer回复Ack应答,此时接受阶段结束,标志本次提案成功,决策形成。之后便是由Proposer角色发送提案对应的Propose,将形成的决策交给Learner执行。
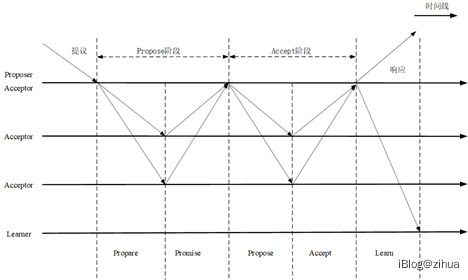
图2.1 Paxos算法流程
原始的Basic-Paxos算法只能针对某一值形成决议,且一次Proposer决议至少涉及与Acceptor的两次独立网络交互,一次交互后如果产生网络割裂的情况下可能导有限等待而形成活锁现象[36]。因此,Basic-Paxos通常只用于理论研究,而不会有对应的工程实现。实际应用中如果想连续决议多个值且能保证程序的正确性和可靠性,那么Mutil-Paxos是解决此问题的一种方法。
Mutil-Paxos针对Basic-Paxos的问题提出了2点改进:1.对每一个要提议的值运行一次Basic-Paxos实例形成决议,且每一个实例都有一个全局唯一的标识(Instance ID)。2.在提议者(Proposer)中进行领导人选举,选出的节点称为Leader。统一由Leader提交Proposal对提议直接进行表决。当Leader被选举出来的情况下,所有的表决只会发生一次网络交互,高效率且避免了各种网络问题。
Mutil-Paxos选出Leader的过程实际上也是一次决议的形成,先通过Basic-Paxos决议出一个Leader,然后由Leader提交Proposal,第一次Proposer与Acceptor的网络交互可以省略,性能得到提升。Mutils-Paxos也允许并发的乱序提交且不影响安全性,但这样的场景Paxos会退化为Basic-Paxos。
在实际的论文中,Mutil-Paxos只是给出一个思路,并没有给出具体的实例和证明。而Zab和Raft算法补充了Mutil-Paxos的细节,并且与论文中Mutil-Paxos有非常多相似的地方,他们比较核心的部分是都会选出一个Leader然后由Leader处理后续流程。
2.4 本章总结
本章介绍了分布式系统相关基本理论,包括CAP和Quorum,这两个理论都是构建一致性算法的基础,一致性的程度取决于二者之间的权衡。Paxos协议给Raft的设计提供了思路,为下文对Raft的研究提供理论依据。
3. Raft算法及其实现
3.1 Raft算法基础
3.1.1 复制状态机
一致性算法通常选用复制状态机[37]结构作为其实现容错的手段。Raft以复制状态机作为其日志复制的依据,所以在讨论具体的Raft之前,需要先了解复制状态机相关的理论依据。
复制状态机在一部分服务器上的本地状态机产生状态相同的执行副本,通过网络传输发送给其他服务器,这样即使在部分机器宕掉的情况下状态机也能继续执行。一个比较典型的应用就是使用由领导人节点管理的状态机负责执行副本的执行和发送,这样可以确保节点宕机的情况下,集群也能对外存活。
状态机理论的基础是:如果集群中的每个节点都运行着相同原型的确定状态机S,且状态机一开始都处于初始状态S0,给予他们相同的输入序列I={i1,i2,i3,i4,i5,...,in},这些状态机会通过执行序列得到转换路径:s0->s1->s2->s3->s4->s5->...->sn,最终达成相同一致的最终状态Sn,同时产生相同的状态输出集合O={o1(s1),o2(s2),o3(s3),o4(s4),o5(s5),...,on(sn)}。
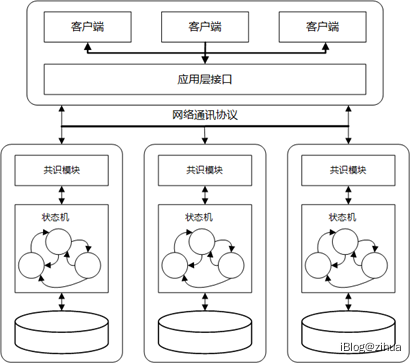
图3.1 复制状态机架构
复制状态机基于日志复制实现,结构通常由共识模块、状态机原型和存储引擎3个部分组成。如图3.1所示,由每一个服务器的共识模块负责接收客户端发起的日志序列并按照接收顺序进行执行和存储,然后通过网络分发日志,使所有服务器节点的状态机达成一致。由于每个状态机的状态是确定的,每一次操作都能产生相同的状态和输出序列,因此,整个服务器集群看起来像形成了一个高可靠的状态机。
3.1.2 节点定义和转换关系
Raft集群通常包含多个服务器节点,一个比较经典的分布式节点是5节点模型,整个系统将会允许容忍任意2个节点发生故障(非拜占庭故障)。根据论文定义,在任意时刻,Raft节点都处于以下三种状态之一:Leader(领导者)、Follower(追随者)和Candidate(候选者)。一般来说大部分场景节点角色都应该处于Leader和Follower,少量发生网络分区则会重新启动领导人选举,会将Follower转变为Candidate参与到选举流程中。
Leader负责统筹所有的客户端请求,与Mutil-Paxos中Leader的作用相同。不同的是,Raft中的Leader处理处理普通的读写请求,还会定时向其他Follower节点发送心跳保持Leader状态,除此之外,日志项在网络中复制也主要由Leader节点传输。Follower为普通节点,大部分场景下负责被动的接受Leader和Candidate传递过来的消息并处理,比如日志复制、日志提交、状态机执行以及领导人选举等等,在部分一致性场景,可以通过约束Quorum直接使用Follower实现一致性的读请求,这样可以不用形成多数派而获得更高效的读性能。Candidate为候选者角色,当Follower节点一次超时心跳时间内未收到Leader发送的心跳包,则会将当前Follower转换为Candidate角色,并向其余节点广播消息启用领导人选举。图3.2展示了这些状态及它们之间的转换关系。
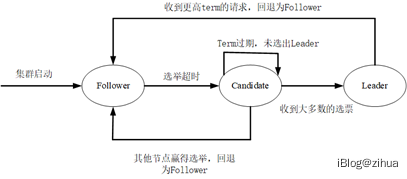
图3.2 服务器状态及转换关系
3.2 领导人选举
Raft按时间划分为任意长度的Term(任期),每一个Term都至少会发生一次领导人选举并选出一个Leader角色,选举结束后,Leader会管理整个集群直到Term结束。大部分场景是能正常选出Leader的,但有时会没有Leader当选而导致选举失败,那么这个Term会因无领导人而结束,每一个Term是按照时间轴顺序递增出现的。
对于不同的服务器节点,可能连续多个Term时间内都无法观察到一次领导人选举。任期号在此处充当全局逻辑时钟[38],当节点与节点交互时会交换子集的Term号,如果任意的服务器当前Term号比其他人小,那么它会将其更新为较大的任期号;如果一个Leader发现集群中出现了比自己更大Term的节点,它会立刻转换为Follower状态;任一节点收到一条小于自身Term的请求时,会直接拒绝。一个比较经典的三节点领导人选举的流程如图3.3所示。
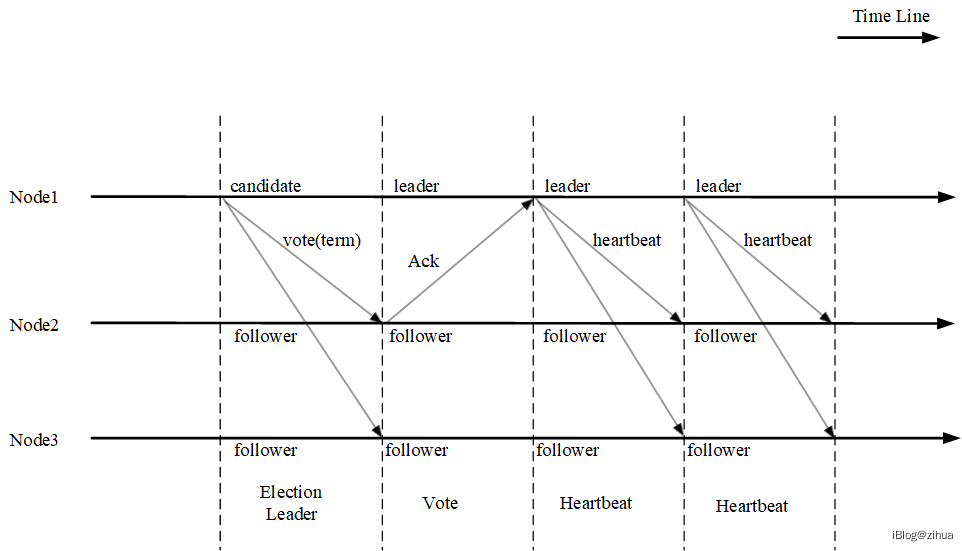
图3.3 三节点Raft领导人选举流程
Raft基于心跳机制来启用领导人选举,程序启动时,节点初始为Follower,由于此时集群并无Leader身份的出现,在等待时间超过一次心跳等待时间时,会将自身转换为Candidate角色并启用领导人选举流程。Candidate会对自身Term+1,然后并行向其他节点发送RequestVote给自己投票。如果发生以下2种情况时,Candidate的状态便不会保持:1. 得到多数派的支持,赢得当前Leader。2. 已经选出了Leader,且〖Term〗_l≥〖Term〗_c。
对于情况1,当一个Candidate得到了集群中的多数派的支持,由于Raft安全性相关限制,每个节点同一Term下只能投票一次,在当前Term下,除了该节点外则不会有其他节点可能获得超过[n⁄2]+1个节点支持。多数派的规则确保了最多只会有一个Candidate赢得选举,而一旦赢得选举,节点会立刻变为Leader,并通过心跳的方式保持自己的领导人状态,其他剩下的Candidate会被降级为Follower。
对于情况2,还需要考虑该Leader的Term是否是最新的,否则依然忽略该Leader。选出了Leader就说明可能存在同级的Candidate得到了多数派的支持,那么此时即便是发起投票也无法获取大多数的票,依然无法成为Leader,所以被降级为Follower。
还有可能出现第3种情况,就是Raft集群形成了超过多数派人数的Candidate角色,由于Raft特性,Candidate不会向其他Candidate投票,所以集群中的每一个Candidate都无法获得多数派支持,Term一直被增大,而Leader不会被选出,满足等待有限等待条件,形成了活锁。
出现这种场景通常是一开始程序启动的时间相近,只要满足Count(Candidate)≥[n⁄2]+1该条件时,程序就会产生活锁现象。Raft算法可以使用随机的选举超时时间,可以给与一个偏差较大的随机范围区间(例如100-2000ms)来确保这种极端场景不会出现,就算发生也依然可以在之后的几次新Term轮回中得到解决。不同的随机超时时间能确保部分进入活锁环路的Candidate角色变为Follower,随着时间的增大,最终还是会形成多数派数量的Follower角色,此时便可以正常进行投票选出Leader。
3.3 日志复制
Raft补充了Mutil-Paxos的细节,针对多决策的提议达成共识的问题逐步分解成三个基本子问题:一是领导人选举,在3.2小节已经详细解释过。二是日志复制,领导人将日志条目作为日志项附加至日志条目中,并通过复制状态机执行日志序列,然后通过网络复制这条日志条目。三是安全性保证,Raft制定了安全性规则,针对领导人选举、日志复制等。第三点在下一小节讲述。Raft中的日志复制是较为核心的部分,也是其实现容错的基本手段。
每一个非只读的客户端请求,都会产生对应的能被复制状态机执行的执行序列。集群中的Leader会将该序列指令作为一个日志项(Log Entry)附加至当前节点的日志集合中去,然后发起并行RPC调用,让其余节点同样附加这个日志条目,当一个日志条目被安全的复制后,Leader会让状态机提交日志序列并将执行结果返回客户端,此时这个提交的日志条目也被称为已提交(committed)。
日志的结构如图3.4所示,主要由一个包含当前任期号Term、日志下标Index和日志条目的三元组组成LogEntry={
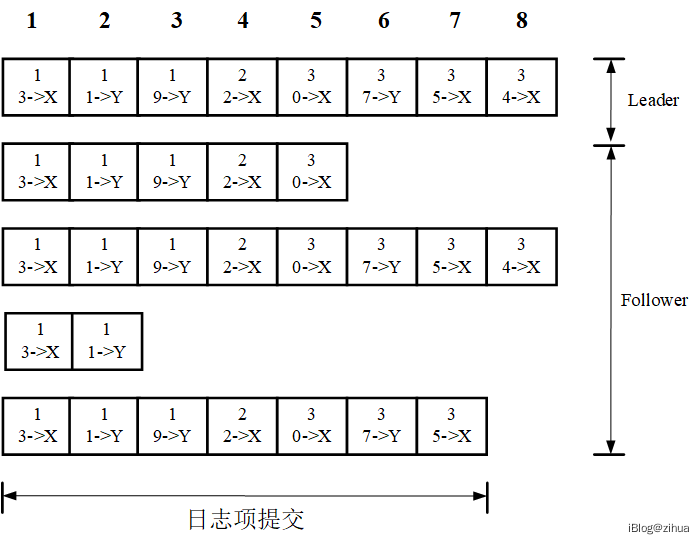
图3.4 Log Entry结构
由Leader决定什么样的日志复制才是安全复制,日志复制保证的是所有被提交的日志条目都会持久化和被状态机执行。如图3.4,可以看到,条目7之前的日志都是被提交状态,因为这些条目都被复制到了至少3个以及上的节点中 ,那么可以称条目7之前的日志都是被安全复制的日志。Leader会维护一个包含最大提交日志项的索引值,以便于向其他节点广播Leader最终提交位置。Follower通过Leader的Ack回复感知到日志条目的提交状态时,它也会将该条目交给本地状态机按照日志的顺序执行。
3.4 日志匹配原则
为了维护不同Raft节点中日志的一致性以及保证日志复制的安全性,Raft拥有日志安全匹配原则,如表3.1所示。

日志匹配原则保证了Raft的2个特性:对于日志结构的三元组LogEntry={
特性1基于以下事实,由于附加原则,Leader在一个term内的指定index位置上只允许创建一个日志条目,这个条目不会被删除和修改,所以它在日志中的位置也不会变。特性2则主要由AppendEntries的一致性检查做保证,所谓的一致性检查,指的是当Leader使用AppendEntries发送附加日志RPC时,Leader会将新条目与上一个条目index和当前term包含在里面,Follower执行时,如果找不到包含相同index位置和term号的条目时,它会拒绝接受AppendEntries请求。特性2的证明实际上是一个反向归纳的过程:每当发现不匹配时,通过一致性检查回退一点index,最终会与Leader前面部分保持完全相同。
3.5 安全性
在所有强Leader的共识算法中,Leader都必须负责存储committed状态的日志。相对的,如果一个节点的日志并不完备,那么这个节点就无法称为Leader。在部分算法中可能存在例外,但如果不保证Leader的日志完备性,则会带来更大的复杂度,这与Raft基于理解性的设计不符。所以Raft通过采用一种更加简单的方法,它保证日志条目单向传递,从Leader传递给Follower,Leader从来不会覆盖自己本地已经存在的条目。
Raft补充了投票的细节来阻止一个不包含完整日志的Candidate赢得选举。如果一个Candidate想赢得选举,就必须获得多数派的ack回复,根据Quroum机制,当Candidate联系超过[n⁄2]+1个节点时,肯定能读到一个包含最新日志的节点。如果此时Candidate的日志完整,那么它必定会包含这个最新的日志。所以对投票RPC做出如下限制,RequestVote包含Candidate最新的Log Entry,并且拒绝掉那些没有自己新的RequestVote请求。可以通过比较Log Entries中的最后一个日志条目下的index和term来判断谁更新。
3.6 本章总结
本章主要介绍Raft相关实现的关键技术,包括复制状态机的定义,介绍了Quorum在Raft集群中如何针对集群选举和日志复制中使所有节点达成共识。
4. 改进的Raft算法及分布式存储模型
4.1 实现分布式存储的挑战
在有了Raft算法之后想实现一种分布式存储模型依然是不够的,因为其大多数开源都是实验性质,比较优秀的业内实现也耦合了很多业务代码,流程整理非常耗时。为此本文试图构建一个简洁高效的Raft库,并在库之上实现其状态机接口从而实现分布式存储模型。为此Raft的模块需要分层足够清晰,方法足够标准,实现手段要求与Paper实现一致,同时模块具有高可用性。本文在这方面做了不小的工作,基于Java实现一个Raft库,并为实现分布式存储模型提供一个良好的基础环境。
4.1.1 Raft的实现
如果不考虑复杂较复杂网络场景的话,Raft确实很容易理解,也能用很朴素的语言表述。如上图5,当不发生任何网络分区时,日志序列的会非常标准且易懂。当引入错停(Fail-Stop)故障模型时,Raft中看似简单的问题变得难以解决,所以,对于其细节的实现非常重要。附录1给出Raft的诸多实现细节,其每一个RPC方法和状态都需要注意,避免因为疏忽和误解导致的实现错误,比如需要持久化的状态没有做保存,那么重启节点可能会产生问题而引起蝴蝶效应,严重的可能会影响到其他节点正常执行。
本文总结了在实现Raft的过程中遇到很容易出现问题的3种错误,活锁、分区恢复以及如何选择RPC服务。这些问题也是实现Raft的较大挑战,理解它们也是很有必要。
4.1.2 活锁
活锁现象经常出现在分布式场景下,在Raft中,最容易产生活锁的地方就是在领导人选举阶段。如果在某个时间段有超过半数的节点同时变为Candidate,且定时器不重置,最终不会有任何领导人会选出,每个节点都将等待其他节点选出Leader,会无休止的等待下去。
造成该活锁现象的一个原因是初始化Raft配置时,给与所有节点不正确的选举超时时间。理论上,超时选举的时间要求应该这样: 广播时间≪选举超时时间≪平均故障时间间隔。一般广播时间为百毫秒级,不会超过1秒;平均故障则一般几个月以上。所以对于选举超时时间的选择,尽可能的在秒级,并且附加一个随机值,随机值的范围也是秒级。这样即便发生活锁,也可以通过新一轮的领导人选举重置定时器从而解放活锁。
4.1.3 分区恢复
发生分区恢复的原因也是由于网络分区,如图4.1(a)所示,一个3节点模型的Raft集群中,C为集群的Leader,而B节点发生了网络分区。在图4.1(b)中,由于心跳超时,B节点定时器重置,开始将自己变为Candidate角色并试图向A和C发起领导人选举的投票请求,由于无法与A、C建立通信,所以B节点的term会不断增大,直到变为n。图4.1(c)中,网络分区恢复,B节点重新与A、C接入,但此时B节点的term非常大,A会投票给B节点从而使C降级为Follower。这种发生分区就强行变更Leader的场景,对性能有很大的影响,因为客户端的读写请求都会重定向给Leader处理,Leader切换的时间内,这些客户端请求要么被丢弃,要么被阻塞,性能上有很大的阻碍。
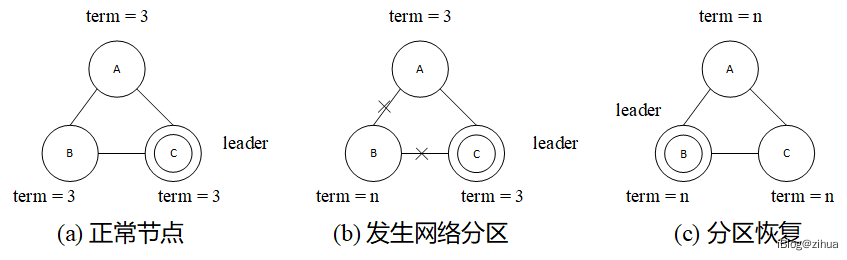
图4.1 分区恢复案例
分析其原因,B节点强制变更Leader主要是由于term的值不断增大,而term的变化的根本是:在RequestVote的RPC函数内,当发起一个投票请求时会将当前的term+1并广播给其他节点。所以这里引入2PC39的RequestVote协议,在调用RequestVote之前先执行一阶段的PreRequestVote,如果PreRequestVote检查无误才会使term+1并广播请求。从而避免term凭空增大。
4.1.4 RPC服务
由于Java语言的特点,框架比语言特性多,RPC框架在互联网领域更是常被使用的框架种类之一,在Raft的实现中,网络通信占据了大量的代码工作,所以如何选择较好的RPC框架也是挑战所在,因为这能让编码工作事半功倍。
Dubbo[40]是阿里开源的一款RPC框架,使用的面比较广,用户群体较多。但据我观察,Dubbo与Spring耦合严重,Dubbo想要正常使用还需要将应用发布至注册中心,耦合度太高且不符合程序简洁朴素的思想。经过仔细研究和慎重考虑,我选择使用Brpc-java作为我程序网络层的主要通信手段,并通过Protobuf规范协议层编码。
4.2 整体设计
4.2.1 架构设计
架构设计如图4.2所示,程序以RaftNode为核心组件,负责连接底层所有服务。
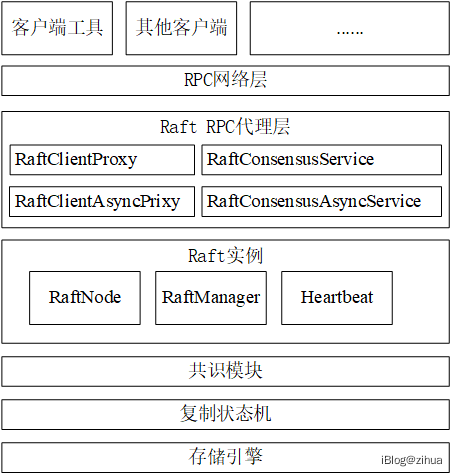
图4.2 存储架构图设计
客户端请求会经过代理层构建出对应请求的RPC代理,然后由RaftNode调度,交给更为底层的ConsensusModule处理,客户端的日志行针对某个值的提议得到多数派的支持后,会往本地服务状态机中提交日志行,状态机会将日志条目持久化交给存储引擎。
系统除了RPC服务是渗透在程序内部之外,其余的每个部分都是解耦的。程序提供通用的状态机接口,将所有针对状态机的操作放在更上一层的业务层去做,在业务层中实现数据存储并通过Raft共识模块进行日志复制从而实现分布式存储模型。
4.2.2 应用程序接口
接口设计基于Protobuf[41],这是由Google提供的一种用于数据交互且具有序列化功能的数据格式,优点主要有跨平台、跨语言且适用于大部分常用语法,包括XML和JSON转换等。体积小,对网络传输带宽负载低;编码解码速度快,可以在CPU下省一点时间。
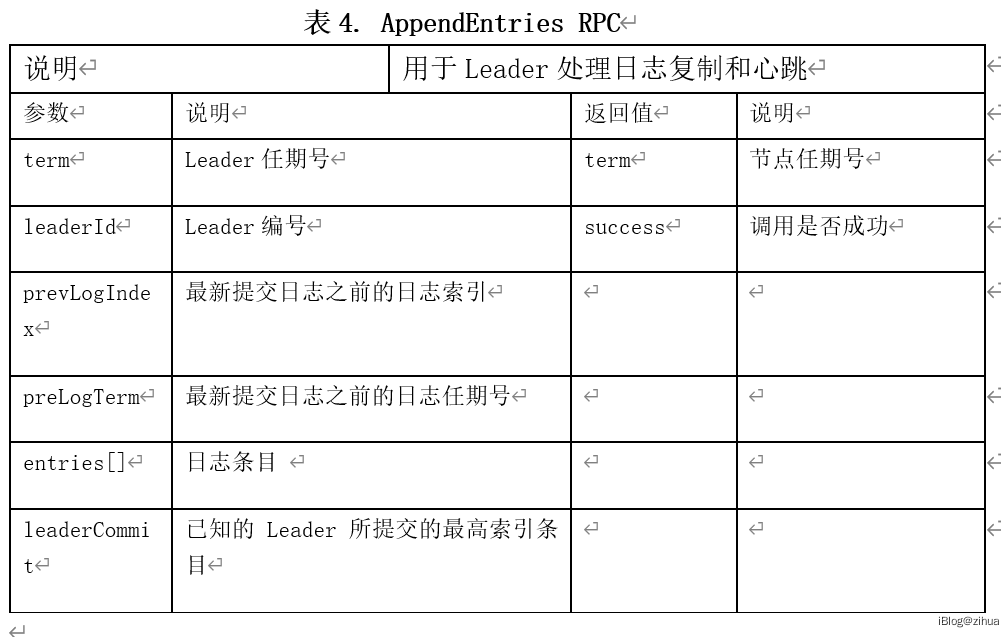
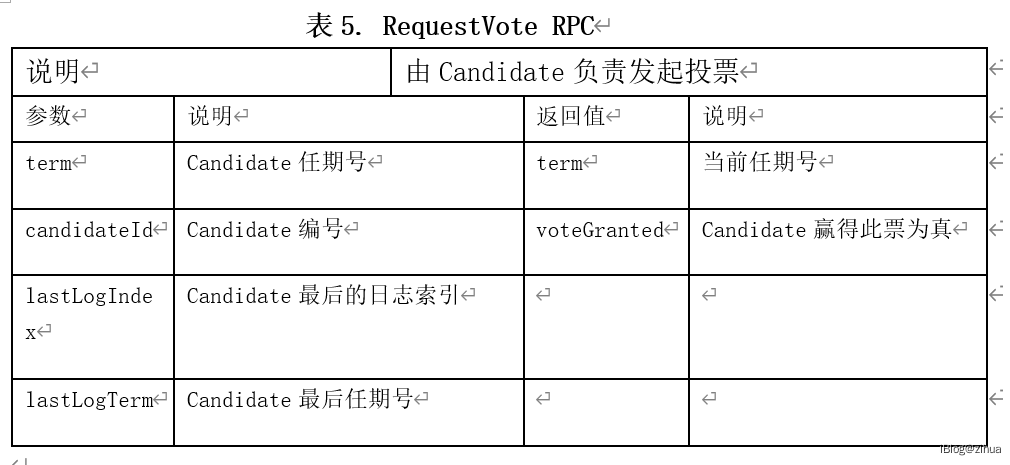
如表4.1所示,基于proto2的语法定制了便于交互的数据接口格式。所有的请求体和响应体完全按照第3章内容实现。
表4.1 接口定义
| 名称 | 类型 | 代码 |
|---|---|---|
| ResCode | 枚举 | enum ResCode { |
| EntryType | 枚举 | enum EntryType { |
| EndPoint | 结构体 | message Endpoint { |
| Server | 结构体 | message Server { |
| LogMateData | 结构体 | message LogMetaData { |
| SnapshotMateData | 结构体 | message SnapshotMetaData { |
| LogEntry | 结构体 | message LogEntry { |
| VoteRequest | 请求体 | message VoteRequest { |
| VoteResponse | 响应体 | message VoteResponse { |
| AppendEntriesRequest | 请求体 | message AppendEntriesRequest { |
| AppendEntriesResponse | 响应体 | message AppendEntriesResponse { |
4.3 RocksDB
RocksDB[42]是一个基于C++编写的嵌入式KV存储引擎,其键值都为二进制数据流,并没有数据结构的概念,由此搭配Protobuf,对数据序列化后直接交给RocksDB做存储效果较好。RocksDB针对Flash存储器做优化,延迟很小。基于LSM-Tree[43](Log-Structured-Merge Tree),依靠大量灵活的配置,使之能针对不同的环境调优,包括使用直接内存、存储介质、硬盘或者直接存在HDFS上都是可行的,且支持使用不同的压缩算法,有一套完整的工具供开发和调试。
RocksDB是由Facebook团队基于LevelDB做二次开发而产生,针对LevelDB的一些痛点做了改进和完善,比如支持HDFS,允许从HDFS直接读取数据、支持Range形式的范围读取、提供Merge操作对多个Put进行合并等、允许单进程多实例,相较于LevelDB,RocksDB的性能更快,使用更便捷。其主要特点如下:
- Key(键)和Value(值)没有数据结构的概念,为数据的字节流,因此存储的内容可以很灵活,比如可以搭配Protobuf对数据序列号然后写入。
- RocksDB存储的KV默认按照Key的顺序排序,这种方式使得对数据做Range查询非常高效。
- 提供WriteBatch、DeleteRange等方法,在批量写入和范围删除有良好的性能。
- 数据支持向前或者向后的迭代遍历。
- 通过Snapshot自动压缩数据。
- 与文件系统解耦。
4.4 针对Single-Raft的优化
4.4.1 算法优化的前提
Raft算法的成立前提与原文献一致,其安全性的设定基本保证了:
- 集群维护一个单调递增的任期号(Term)。
- 集群间的网络通信并不可靠,比如发生丢包、延迟、网络抖动等。
- 不产生拜占庭错误。
- 集群中总是会选出一个Leader且同一任期号下只仅会有一个Leader。
- 由Leader负责与客户端请求交互,其他节点收到的客户端请求需要重定向到Leader。
- 针对客户端的请求满足线性一致,且客户端操作后都能准确的返回交互信息。
但在实际工程项目中,机房之间的通信大部分时间都会趋近于稳定(即节点之间的延迟远远小于一次Heartbeat的时间),且一般的可靠通信协议如TCP会有重传机制,丢包也会立即重传,这使得即便发生故障也能短时间恢复并且趋近于稳定,所以改进的前提是2不成立,即计算机网络不总是处于一个危险的状态。假设认为Leader与其他Follower建立的通信是安全的,不会经常性的随意发生节点宕机和网络分区。
4.4.2 Proposal处理
客户端的每个针对服务端且能被状态机执行的操作称为一次Proposal,一次完整的Proposal流程通常由事件请求(Invocation,下称Inv)和事件响应(Response,下称Res)组成,一个请求包含一个具有Write或者Read类型的操作,非只读类型的Write最终被状态机提交。
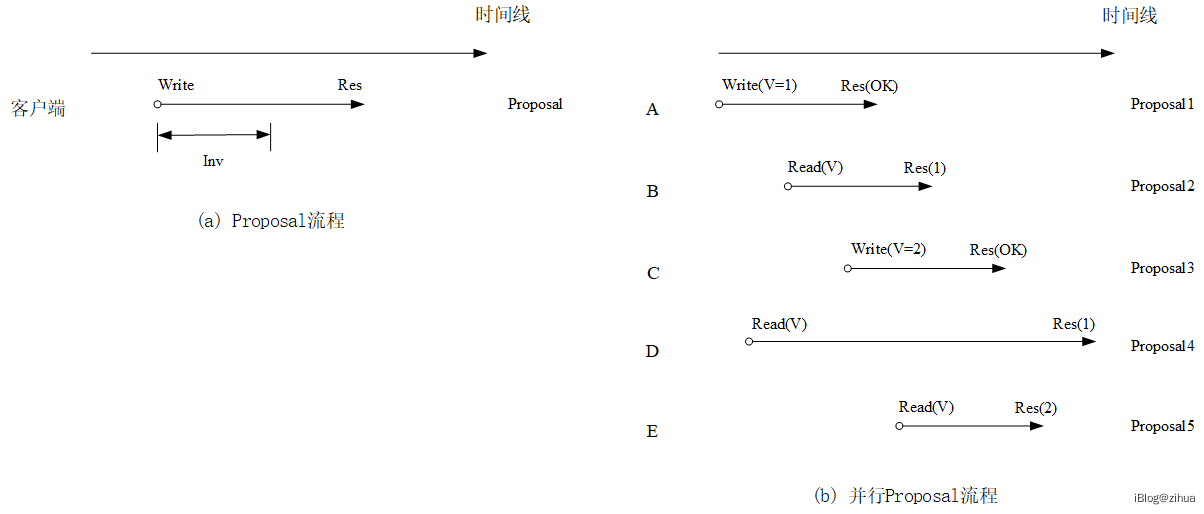
图4.3 客户端Proposal处理流程
如图4.3(a),展示了由客户端A的一次Proposal从发起到响应的过程。从Raft角度来看,满足线性一致性的系统需要达成如下几点:
- Proposal的提交可能是并发的,但处理都是顺序的,在一个Proposal返回响应之后才能处理下一个Proposal。
- Inv操作满足原子性。
- 其他Proposal发生在Inv和Res两个事件之间。
- 任何一个Read操作返回新值后,后续所有的Read操作都需要返回新值。
图4.3(b)是Raft中并行客户端请求但满足线性一致性的例子。对同一份数据V,客户端ABCDE在某一个时刻发起并行的Read/Write请求,Raft按照真实时间(Real-Time)顺序接收Proposal如图所示,请求满足如下的全序关系:
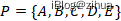
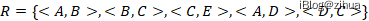
A发起写入的V=1在Inv时间段写成功,此时B在Inv到Res之间的时间发起读,那么能则会读到V=1,同理C和E类似。D的读操作在A之后在C之前,那么此时D读到的值则是由A发起的Inv的数据,会返回V=1。
4.4.3 改进的Raft算法流程
Raft本身的线性语义导致即便是并发的客户端请求,最终都会转变为执行序列被顺序接、执行和提交。在大量级的并发请求下,会出现两个问题:①Raft机制下Proposal都必须经过Leader处理,Leader很容易成为性能瓶颈 ②处理速率<<请求速率,大量请求会造成大量日志堆积,长时间占用带宽和内存。
针对问题1,目前已经有基于Mutil-Raft-Group[44]的实现。Mutil-Raft把一个Raft集群作为一个共识组,每个共识组都会产生一个Leader,由不同的Leader管理不同的日志分片,这样Leader的负载压力则会均分到所有共识组中,从而避免单Raft集群的Leader成为障碍。本文主要把问题放在如何解决问题2上。

图4.4 日志条目提交流程
每一个Proposal会被转换成能被状态机执行的日志,如图4.4,当Leader节点的一致性模块接收到日志,Leader首先会将日志附加到日志集合中,然后通过RPC方法AppendEntries将日志项分发到其余Follower节点中,在不考虑诸如网络分区和宕机的条件下,Follower节点接受到请求也会将日志项复制到自身日志集合中并回复Leader节点ACK表示成功Append,Leader接收到超过半数的Follower的ACK消息时,会使用状态机提交日志,并发送ACK让其他Follower节点也提交,从而完成一次集群的日志提交。
并发场景下,待处理的日志项的可以理解为一种无限增长的任务队列,Leader不断的向Follower发送Append Entries的RPC消息并等待得到半数节点响应的时间段内,这个队列增长率远远大于一次日志被提交的时间,在这种日志同步模式下,再考虑到网络抖动和丢包重传的时间,被影响的日志会更多,对系统吞吐量影响很大。
基于TCP协议的滑动窗口机制,当发起多个连续的Append Entries RPC时,Leader本质上是与Follower建立了TCP关系并发起了多个分组的TCP数据包,滑动窗口机制下允许发送方在停止等待确认前连续发送多个分组,而不必每次发送一个组就停下来确认。窗口大小决定了能发送的数据包数量,窗口满了则会延迟等待。而大量TCP数据包的延迟等待会导致LFN(LFN, long fat network)的出现,这会使得数据包超时到达接受方而选择重传,无用的重传产生了很大的网络开销。如果窗口足够大,那么连续发送多个数据包都能正确收到响应且不会重传,不算其他网络开销的话此时网络吞吐量等同于每秒数据传输量。
在此理论上将连续的Append Entries的同步等待改为异步,这样后续的ACK不会被阻塞,网络吞吐量能得到提升。但如此做也增加了算法的实现难度,异步回调时由于操作系统调度的影响,可能会出现异步处理的消息顺序不一致,如果直接异步提交可能会导致日志空洞现象。解决方法是当Leader连续的多条Heartbeat确认都能及时得到响应,那么认为此时网络是顺畅的,即便是乱序也是在可控范围内,即在未来的某个时间点一定会出现这条乱序日志之前的日志,只是由于调度问题产生的乱序,那么只需要等待再顺序提交即可。如果网络发生故障和分区,TCP的机制也保证了消息不会乱序。
在此异步的基础之上对日志的处理使用批处理的方式。为此引入Pre-Proposal阶段用来对并发的Proposal做预处理,如图4.5所示。Pre-Proposal阶段处于客户端发起的Proposal到Leader处理这个Proposal之间,这个时间段内使用一个并发性较强同步队列依照FIFO(FIFO, First Input First Output)的顺序装入Proposal。Leader开始处理Proposal之后,会从同步队列中顺序取出Proposal直到遇到队列中第一个只读请求。然后构造一个与本地状态机完全相同的副本状态机,在副本状态机中批量提交非只读日志,抽离出快照,通过Install Shapshot发送异步RPC使其他Follower节点安装快照,当收到来自大多数节点的ACK响应时,使用副本状态机替换原来的状态机。为了保证Raft的一致性读,所以一个读请求在执行前必须保证写请求已经执行完毕,为此需要阻塞同步队列,对读相关的Proposal则单独处理,直至下一个读请求。经测验,在写多读少的场景下,吞吐量相比于传统Raft有极大的提升。
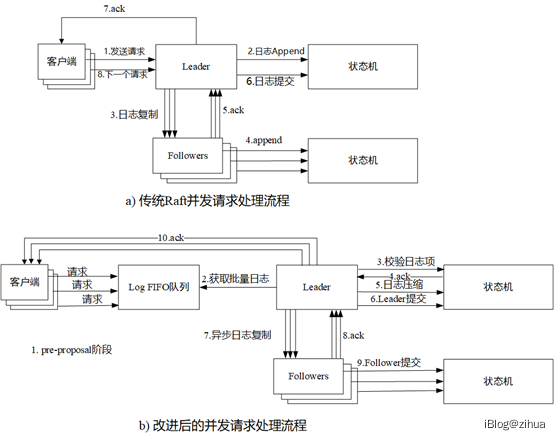
图4.5 Raft并发请求流程
4.5 本章总结
本章基于实现的Raft算法,针对Raft算法的问题提出优化方案,以及介绍了使用RocksDB构建对应的分布式存储模型还有接口、架构设计,为分布式存储服务提供基本思路。
5. 性能测试与分析
5.1 系统环境
为了验证系统的正确性以及性能,本文对基于优化后的Raft算法构建的分布式存储系统做了对比分析和实验,测试系统正确性与性能提升比率。实验环境如下:由一台服务器主机内存16GiB,CPU为Intel Xeon(Cascade Lake) Platinum 8269CY 2.5GHz,机器为8核。将程序跑在此服务器的虚拟化容器中,启动3-5个节点,每个节点指定4GiB内存和2个CPU核心,操作系统为CentOS,程序代码使用Java完成。
5.2 正确性验证
不产生复杂故障场景时,分布式系统的行为都是可预测且容易理解的。本文一直强调的一个要点是,分布式系统中最核心的特点就是能自动处理容错。但对于稍微复杂点的网络模型故障是天然特性,比如消息乱序、丢包、网络分区、链路故障等无法完全避免。基于这种不稳定场景,没有得到正确性证明的分布式系统服务会在实际环境中曝露出各种问题和bug,这是任何人都不愿意看到的。为了保证系统的正确性,本文引入了一些验证手段来模拟测试,包括对领导人选举、日志复制以及持久化特性做出验证。
5.2.1 领导人选举测试
领导人选举的功能的正确性,实验环境准备一个包含5节点的Raft实例集群,主要检验能否在不同网络环境下依然能按照要求选出Leader。
设定Raft参数中选举超时时间为1000ms,心跳周期为500ms,测试集群能否在启动后5000ms之内合法选出Leader。停掉当前Leader,统计新Leader选举的时间。将该实验重复执行10次,最终得出实验次数与选举时间的关系图如图5.1所示。
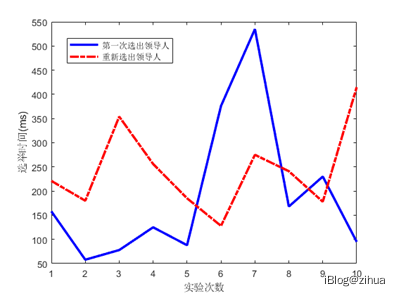
图5.1 选举时间随实验次数统计图
从数据中可以看出,选举成功时间是无规律的,主要是由于领导人选举也受到CPU调度的影响,但从数据上看,最坏的情况也不会超过600ms。所以能得出一个结论:在复杂场景下,单次领导人选举的时间为毫秒级别。
5.2.2 日志复制测试
日志复制是Raft集群对日志条目达成共识的手段,是整个Raft算法中比较核心的部分,其内部主要通过复制状态机来执行被提交的日志条目来实现。为了满足系统能在故障条件下也能提供服务,提出以下几个测试方案:
- 往集群中写入x=1,然后读x。
- 停掉任意两个节点,读x。
- 停掉任意三个以上的节点,但不超过五个,然后写入x=2。
- 停掉任意两个节点,然后写入x=3,再读x。
按照Raft规则,方案1能正常读取到x=1;方案2即便停掉了2个节点,但仍然能形成多数派,所以能正常读到x=1;方案3停掉了多数派的节点,所以此时应该不允许日志复制,也就是说,该写入无效;方案4停掉少数派节点然后写入,所以能正常读到最终的x=3。具体的实验结果如表5.1所示:
表5.1 日志复制测试
| 方案编号 | 预期结论 | 实际结果 |
|---|---|---|
| 1 | {success,x=1} | {success,x=1} |
| 2 | {success,x=1} | {success,x=1} |
| 3 | {fail,} | {fail,time out exception} |
| 4 | {success,x=3} | {success,x=3} |
从测试结果中可以看出,只要满足多数派的读写前提,则日志复制是正确的,即便是方案3这种错误场景也能给出报错提示和异常,这是满足系统可用性要求的。
5.2.3 故障恢复测试
Raft节点状态包含易失和持久两种类型,有一些状态时易失的,比如待提交的日志索引(commitIndex)和已经被应用的最高日志条目(lastApplied),当选出Leader之后会时刻给其他节点广播数据,所以这些状态无需被持久化。但有一些状态,比如节点任期号(term)、任期内的投票权(voteFor)以及日志条目(logEntries)是需要被持久化保存的。
对于任期号和投票权,假设一个比较极端的场景:正在进行领导人选举,此时一个Follower角色给另外一个Candidate角色投票然后就被Crash了,由于投票权和任期号不保存,该Follower角色重新上线后,依然会在当前任期下再次拥有投票权,如此一来,极端场景下是可能发生多次投票,从而破坏安全性约定。所以任期号和投票权必须持久化存储,以免发生重新上线后产生拜占庭故障。
对于日志条目,如果集群已经运行了一段时间,那么所产生的日志条目数量会较多。如果已经Crash的节点重新上线,Leader会主动发送日志条目给Follower,如此一来,占用了不必要的带宽和网络资源。本地IO操作优先于网络IO操作,所以对于日志条目这种类型的状态也需要持久化保存。
为了验证系统宕机后的恢复能力,我设定了如下流程:
- 启动一个5节点的Raft集群。记录当前term和leaderId
- 往集群连续发送数十次写请求,并记录其关键key。
- Crash并重启所有节点,等待数毫秒。
- 使用关键Key验证日志是否持久化保存,观察Leader是否发生过变更。
按照以上流程连续写入序列{<x,1>,<y,2>,<z,3>,<a,4>,<b,5>,<c,6>},重复实验10次,得出如表5.2中的结论:
表5.2 故障恢复测试
| 问题 | (结果数量/实验次数) |
|---|---|
| Leader发生变更次数 | 2/10 |
| 读取关键Key的结果集符合预期结果数量 | 10/10 |
发现Leader之所以有2次发生变化主要是因为CPU调度和启动的先后顺序,我们不能百分百保证旧的Leader节点总是优于其他节点的启动,而对于Raft集群来说,只要选举超时,那么就会废弃掉原来的Leader而产生新Leader,如果产生连续3个比旧Leader更快的节点时,此时已满足形成新Leader的条件,于是从这几个节点中产生新Leader。正常情况下这种事件的发生是小概率的,但这2个不符合预期的结果主要是因为我是手动随机启动,所以对此结果也是有所预料。综上所述,系统的故障恢复能力是正确的。
5.3 性能对比
为了评估文中提出改进的Raft算法的效率,与传统的Raft[23]做对照试验,并通过以下2个方面来评估:①改进前后处理相同量级Proposal所花费的时间;②改进前后对系统吞吐量的影响。
表5.3记录了改进后的算法在系统吞吐量以及日志处理上的提升率。可以看出优化后的算法使得系统吞吐量能至少提升一倍,处理客户端请求也能提升20%以上。
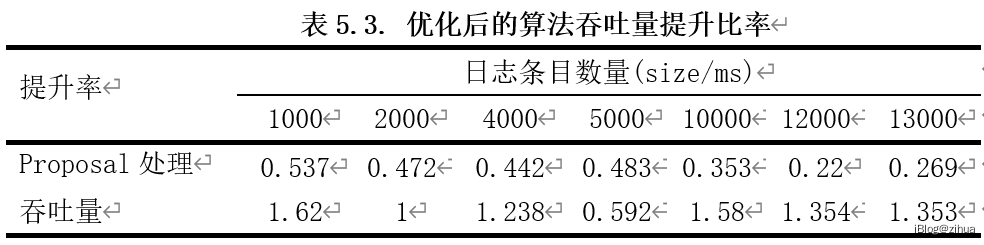
对于实验①②设定了17组对照实验,请求并发量最高达13000,使用多线程分别对两种系统发送并发请求,最终结果如图11和表6,相对于传统算法能有不错的性能提升。
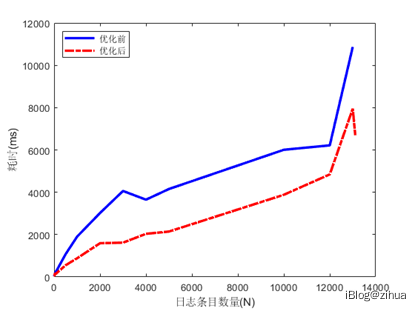
图5.2 日志条目随时间变化的性能比较
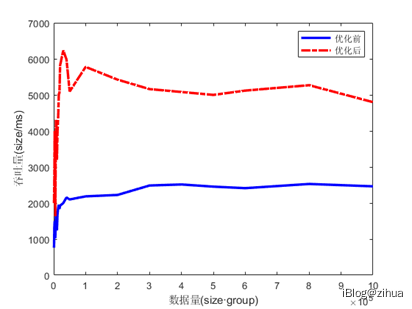
图5.3 比较改进前后系统吞吐量
随着并发量不断增加,程序必然会带来处理瓶颈(即处理速率<<任务递增量),图5.2可以看出在当前硬件环境下12000左右的日志并发会是一个瓶颈,两组程序在这个时间点之后的处理能力呈指数级下降。在瓶颈线之前可以明显的看出改进后的算法相比传统的算法能稳定保证20%以上的提升。瓶颈线之后,由于改进后的算法能对并发的任务队列进行批处理,所以增长率从指数级下降为线性后趋近于稳定,而传统的算法由于日志积压和任务堆积,处理能力会一直呈指数趋势。
图5.3可以看出随着处理数据量的提升,通过批处理处理数据的方式能够保证改进后的程序系统吞吐量始终在传统程序之上。由于硬件和软件系统的诸多限制(包括磁盘机械臂数量、CPU核心数、文件系统等),这个提升并不会太过于明显。即便如此,相对来说吞吐量也能稳定保证在原有程序的2倍以上。
5.4 本章总结
本章通过对前4章的内容,设计出针对系统的测试方案,包括手动构建网络分区判断是能容错以及构建高并发场景的写测试对优化方案进行性能对比,最后通过实验数据证明了系统的正确性和可行性。
6. 全文总结
6.1 本文工作总结
本文以分布式系统中最为核心的基于复制状态机容错的一致性问题作为展开,调研了诸多一致性算法,Zab和View Replcation是作为商业开源软件核心组件而存在的,虽然都有单独的文章,但并未提供较好的实现思路。Paxos作为一致性算法的标准,只研究Basic-Paxos,在工业领域内没有实际意义,而研究Mutil-Paxos又和前面几个算法一样,一是难实现和难理解,二是没有相关实现标准和形式化验证手段。故选择研究Raft,并深究其在分布式系统中的实践。
一致性算法主要讨论的问题是容错,也就是即便产生任意故障也能正常执行。为此,本文规定了所探讨的故障模型,即保证所产生的故障在错停模型(Fail-Stop)之上,在拜占庭故障(Byzantine)之下。基于这些设定场景,本文使用Raft实现了完整的复制状态机,并在此基础之上建立了一个分布式存储模型。在这个模型内,对整体系统设计相关验证手段并测试其正确性。本文的研究成果如下:
- 通过横向分析现有可行分布式共识算法后,选择深入研究Raft。在翻阅大部分开源代码之后,发现这些开源实现的并不完整,综合之后选择自己构建Raft的共识模块,并提供了一个状态机接口。通过构建在Raft模块之上的分布式存储模型,给分布式存储服务提供基本思路。为了验证系统的可用性,本文引入测试手段对领导人选举和日志复制等关键功能进行测试,根据实验5.2.1-5.2.3结果显示,不同网络分区环境下,均能达到预期的结果。
- 基于易用的Raft实现,共识模块与上层的应用层和下层的存储层均解耦合。本文进一步完善Raft模块,针对其在较大并发场景下的性能问题做出改进,在其基础上引入Pre-Proposal阶段,通过批处理异步复制日志和异步刷盘来实现并发性能的提升。最后通过实验的实验5.3结果证明了改进后的Raft能提升2-3.6倍的系统吞吐量,对于并行请求的处理效率最少提升20%。
本文通过实现完整的Raft协议,以此为展开建立了基于Raft协议的分布式存储模型,构建了一个满足一致性需求且具有故障容错能力的分布式存储服务,为此提供了一套完整的解决方案,最终的实验也达到了预期的目标。
6.2 未来工作展望
根据文中已经完成的工作,进一步可以从一下几个方面入手:
-
文中实现的Raft协议基于Java语言,Java语言一直以简单易用著称,但实际并非如此,在实现Raft过程中我深切体会到其诸多不便:一方面是性能,另一方面是Java语法个性化程度太高。性能方面,Java的执行依赖于JVM(Java Virtual Machine, Java虚拟机),最终编写好的代码会编译为字节码放在虚拟机中执行, 基于这种解释型的执行方式,和C/Go/C++这种可以直接编译为可执行程序并让CPU执行的语言,性能上肯定有所不足。虽然Java社区一直在宣传JIT(Just In Time, 即时编译)技术多么强悍,但基于栈执行结构就肯定有入栈和出栈的动作,其所额外消耗的CPU时钟是始终存在的。故可以使用性能更加接近操作系统级别的编译型语言实现,性能上会有所提升。语法方面,Java提供了大量的三方库、诸多新概念锁以及各种各样语法糖。复杂的语法糖只能给编写代码的人带来比较好的体验,但对其他想阅读代码并参与贡献的人来说,这是一种折磨,而编写的软件越偏向于系统层,就需要更加简洁的代码,我认为Java在这方面是比较致命的。综合性能和语法各方面角度的考虑,我提议可以选择使用Golang来作为下一步工作的语言。
-
文中在4.4.3中提出的问题一,目前虽然已经有基于Mutil-Raft-Group的良好实现,但它主要作为Cockroachdb的一部分。所以可以继续在Raft基础上实现Mutil-Raft-Group,并提供一套抽象接口。
-
文中的分布式存储服务使用RocksDB作为存储引擎,RocksDB足够优秀,确实可以适应大部分业务场景,但它也存在问题。比如写放大严重、索引效率低、压缩率有限。针对这些问题,其他的存储引擎或许能解决,但又无法得到RocksDB这么好的性能。所以我提议,在存储层之上引入动态存储层,允许动态引入其他类似于Hash、B+、B-、LSM-Tree等引擎,以便适应更多场景得到良好的性能。
附录



致谢
转眼间,本科学习即将画上句号,回顾本科学习的这段时间,收获不可谓不多。我的心中充满感激和不舍,真心感谢一路上的所有人。
首先感谢指导老师李皞老师,给与了我科研方面很多指导。这次本科毕业设计流程中,在老师的指导下,成功合作发表了一篇文章,这次经历让我掌握了怎么研究我不擅长的事物的手段。
我也非常感谢其他的专业老师和辅导员,在我本科期间学业和生活上给与了不小的帮助,这一路成长的路上,离不开每一位老师提供专业的知识解答和生活上的帮助。
还有我本科期间的同学们,你们是我这一路上必不可少的伙伴,每每有课程疑问或者其他方面的问题都会和你们共同探讨,这使得我大学学习和生活更加丰富。
最后我要感谢我的家人和朋友们,感谢你们在我学习的路上长期默默支持和鼓舞,你们永远是我前进的动力,谢谢你们。
参考文献
- Bianca Schroeder and Garth A. Gibson. 2007. Understanding disk failure rates: What does an MTTF of 1,000,000 hours mean to you? ACM Trans. Storage 3, 3 (October 2007), 8–es. DOI:https://doi.org/10.1145/1288783.1288785 (磁盘故障的具体数据)
- J. Dean. Handling Large Datasets at Google: Current Systems and Future Directions. In Data-Intensive Computing Symposium, 2008.(服务器宕机数据)
- Phillipa Gill, Navendu Jain, and Nachiappan Nagappan. 2011. Understanding network failures in data centers: measurement, analysis, and implications. SIGCOMM Comput. Commun. Rev. 41, 4 (August 2011), 350–361. (网络分区1)
- Robinson H. CAP Confusion: Problems with ‘partition tolerance,’[J]. Cloudera Engineering Blog, 2010.(网络分区2)
- Susan B. Davidson, Hector Garcia-Molina, and Dale Skeen. 1985. Consistency in a partitioned network: a survey. ACM Comput. Surv. 17, 3 (Sept. 1985), 341–370. DOI:https://doi.org/10.1145/5505.5508(网络分区3)
- Lamport L, Shostak R, Pease M. The Byzantine generals problem[M]//Concurrency: the Works of Leslie Lamport. 2019: 203-226.(拜占庭容错)
- Schlichting R D, Schneider F B. Fail-stop processors: An approach to designing fault-tolerant computing systems[J]. ACM Transactions on Computer Systems (TOCS), 1983, 1(3): 222-238.(错停)
- Schneider F B. Implementing fault-tolerant services using the state machine approach: A tutorial[J]. ACM Computing Surveys (CSUR), 1990, 22(4): 299-319.(复制状态机容错)
- Frömmgen A, Haas S, Pfannemüller M, et al. 2017. Switching ZooKeeper’s consensus protocol at runtime. 2017 IEEE International Conference on Autonomic Computing (ICAC). pp 81-82.(Zookeeper)
- website. https://github.com/tikv/tikv(tikv)
- Ailijiang A, Charapko A, Demirbas M. 2016. Consensus in the cloud: Paxos systems demystified. 25th International Conference on Computer Communication and Networks (ICCCN). pp 1-10.(chubby)
- Brewer E 2017. Spanner, TrueTime and the CAP Theorem.(分布式数据库1)
- Huang D, Liu Q, Cui Q, et al. 2020. TiDB: a Raft-based HTAP database. Proceedings of the VLDB Endowment, 13(12): 3072-3084.(分布式数据库2)
- Taft R, Sharif I, Matei A, et al. 2020. Cockroachdb: The resilient geo-distributed SQL database. Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 1493-1509.(分布式数据库3)
- Huang D, Ma X and Zhang S 2020. Performance Analysis of the Raft Consensus Algorithm for Private Blockchains, IEEE Transactions on Systems, Man, and Cybernetics: Systems, 50(1): 172-181.(区块链技术1)
16 Mingxiao D, Xiaofeng M, Zhe Z, Xiangwei W and Qijun C 2017. A review on consensus algorithm of blockchain. IEEE International Conference on Systems, Man, and Cybernetics (SMC), (Banff, AB, Canada) pp. 2567-2572(区块链技术2) - Guozhang Wang, Joel Koshy, Sriram Subramanian, Kartik Paramasivam, Mammad Zadeh, Neha Narkhede, Jun Rao, Jay Kreps, and Joe Stein. 2015. Building a replicated logging system with Apache Kafka. Proc. VLDB Endow. 8(12): 1654–1655.(中间件技术)
- Robbert Van Renesse and Deniz Altinbuken. 2015. Paxos Made Moderately Complex. ACM Comput. Surv. 47 (3) p 36.(Paxos)
- Boyd S, Ghosh A, Prabhakar B, et al. Randomized gossip algorithms[J]. IEEE transactions on information theory, 2006, 52(6): 2508-2530.(Gossip)
- Oki B M, Liskov B H. Viewstamped replication: A new primary copy method to support highly-available distributed systems[C]//Proceedings of the seventh annual ACM Symposium on Principles of distributed computing. 1988: 8-17.(ViewStamped Replcation)
- Junqueira F P, Reed B C, Serafini M. Zab: High-performance broadcast for primary-backup systems[C]//2011 IEEE/IFIP 41st International Conference on Dependable Systems & Networks (DSN). IEEE, 2011: 245-256.(Zab)
- Lakshman A, Malik P. Cassandra: a decentralized structured storage system[J]. ACM SIGOPS Operating Systems Review, 2010, 44(2): 35-40.(Cassandra)
- Ongaro, Diego, and John Ousterhout. 2014. In search of an understandable consensus algorithm. 2014 USENIX Annual Technical Conference. pp 305-319.(raft)
- Huang D, Liu Q, Cui Q, et al. 2020. TiDB: a Raft-based HTAP database. Proceedings of the VLDB Endowment, 13(12): 3072-3084.(tidb)
- website. https://www.oceanbase.com/ (oceanbase)
- website. https://github.com/Tencent/phxpaxos(PhxPaxos)
- website. https://raft.github.io/#implementations(raft实现列表)
- website. https://github.com/etcd-io/etcd(etcd)
- website. https://github.com/tikv/tikv(tikv)
- website. https://github.com/rethinkdb/rethinkdb(rethinkdb)
- Chaudhuri S, Dayal U. An overview of data warehousing and OLAP technology[J]. ACM Sigmod record, 1997, 26(1): 65-74.(olap)
- Karun A K, Chitharanjan K. A review on hadoop—HDFS infrastructure extensions[C]//2013 IEEE conference on information & communication technologies. IEEE, 2013: 132-137.(hdfs)
- Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[J]. HotCloud, 2010, 10(10-10): 95.(spark)
- Kleppmann M 2015. A Critique of the CAP Theorem. arXiv preprint arXiv:1509.05393.(cap)
- Aiyer A, Alvisi L, Bazzi R A. On the availability of non-strict quorum systems[C]//International Symposium on Distributed Computing. Springer, Berlin, Heidelberg, 2005: 48-62.(quorum)
- Ho A, Smith S, Hand S. On deadlock, livelock, and forward progress[R]. University of Cambridge, Computer Laboratory, 2005.(livelock)
- Schneider F B. Replication management using the state-machine approach, distributed systems[J]. 1993.(rsm)
- Leslie Lamport. 2019. Time, clocks, and the ordering of events in a distributed system. Concurrency: the Works of Leslie Lamport. (New York, USA) pp 179–196.(clock)
- Lampson B, Lomet D. A new presumed commit optimization for two phase commit[J]. 1993.(2pc)
- website. http://dubbo.io/(dubbo)
- website. https://developers.google.cn/protocol-buffers/(protobuf)
- Yang F, Dou K, Chen S, et al. Optimizing NoSQL DB on flash: a case study of RocksDB[C]//2015 IEEE 12th Intl Conf on Ubiquitous Intelligence and Computing and 2015 IEEE 12th Intl Conf on Autonomic and Trusted Computing and 2015 IEEE 15th Intl Conf on Scalable Computing and Communications and Its Associated Workshops (UIC-ATC-ScalCom). IEEE, 2015: 1062-1069.(rocksdb)
- O’Neil P, Cheng E, Gawlick D, et al. The log-structured merge-tree (LSM-tree)[J]. Acta Informatica, 1996, 33(4): 351-385.(LSM-Tree)
- Taft R, Sharif I, Matei A, et al. 2020. Cockroachdb: The resilient geo-distributed SQL database. Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 1493-1509.(mutil-raft)

