mark
由于个人的一些原因,本文先搁置
引言
本文旨在解析AskBend和OpenAI提供的embedding实现一个mysql的AI知识问答接口,本文中您会看到如下内容:
- AskBend源码解析
- OpenAI提供的fine-tune和embedding是什么
- OpenAI如何提升completion的回答质量
- 实现一个mysql-based knowledge的基本流程
OpenAI
关于fine-tune
fine-tune,一般称之为微调,openai地址
fine-tune的原理是在不改动预训练模型的基础上,在模型顶层增加分类器或一些特征映射,使微调后的模型能更加贴合实际使用场景。
在OpenAI中,可以不改动GPT-3大模型的情况下,针对prompt和completion的进行训练,对句式、情感等特征进行优化。
GPT-3已经预训练大量互联网内容。只需要在prompt里写少量的用例,基本可以感知你的用意并生成一段合理的completion。这个功能一般叫做"few-shot learning"。
fine-tune基于few-shot learning,通过训练比写在prompt更多的实例,可以得到更好的结果。模型被微调后,就不用在prompt里写一些实例了,可以节省成本和耗时。
使用场景如:
- 想让GPT-3按照某种格式来识别Prompt,或按照某种格式来回答
- 想让GPT-3按照某种语气、性格回答
- 想让completion具有某种倾向
关于embedding
embedding,一般称之为嵌入,openai地址
embedding是指将一个内容实体映射为低维向量,从而可以获取内容之间的相似度。
OpenAI的embedding是计算文本与维度的相关性,默认的ada-002模型会将文本解析为1536个维度。用户可以通过文本之间的embedding计算相似度。
embedding的使用场景是可以根据用户提供的语料片段与prompt内容计算相关度,然后将最相关的语料片段作为上下文放到prompt中,以提高completion的准确率。
使用场景:
- 获取文本特征向量
- 提供相关上下文,让GPT-3根据上下文回答
如何提升回答的准确率?
OpenAI提供了completion api来实现问答,但是只提供了固定的模型,用户不能修改他的模型,不过可以使用fine-tune来生成自己的模型,如果我们拥有一个mysql的文档库(语料库),那么结合起来能生成专属于mysql文档的问答程序。
使用fine-tune能对最终的completion质量做优化,虽然fine-tune能稍微提升质量,让API更好的理解提供的prompt并输出一个预期结果。一般情况下 ,训练一个模型需要先提供example然后再提供context,使用fine-tune只需要提供相同的prompt的token,然后openai就会利用fine-tune学到的知识自动返回yes或者no。如果不进行fine-tune那么每次token都需要先提供一个example。
可见如果使用fine-tune可以节省大量的token(省钱)。
目前为了提高回答准确率,有2个优化方向:
- 增加数据集
- 增加上下文,且答案就在上下文中
OpenAI不允许用户训练数据,他的模型固定且通用,所以不能增加数据集。那么只能使用方法2:增加山下文。
我们可以在prompt前后增加上下文来提高completion的准确率。首先需要从我们自己的语料库(大量语料片段组成)中找到提问相关的上下文,这里需要用OpenAI提供的embedding接口,它的api参考如下:
request:
{
"model": "text-embedding-ada-002",
"input": "The food was delicious and the waiter..."
}
response:
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [
0.0023064255,
-0.009327292,
.... (1536 floats total for ada-002)
-0.0028842222,
],
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}
指定model并提供input,由openai计算并返回emedding向量值。
我们可以通过将"语料片段的向量"与"问题的向量",取"相似的向量",来判断问题和语料片段的相似度(similarity)。这样我们在prompt里把最相似的语料片段作为context放进prompt就可以得到最正确的completion。
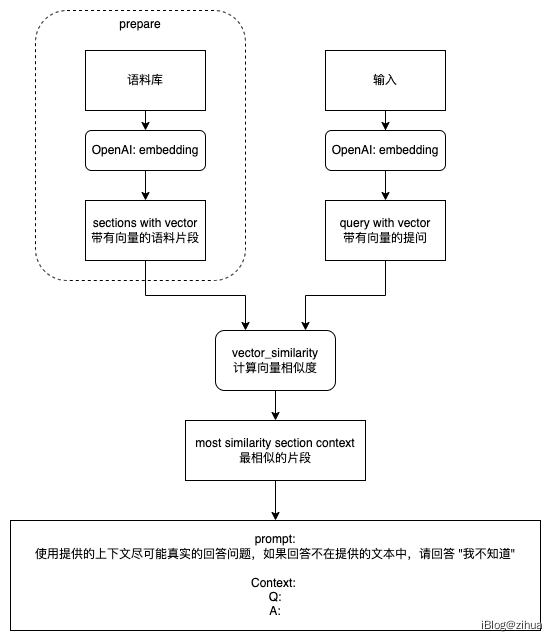
相似度计算算法参考余弦相似度(Cosine similarity)。
AskBend源码解析
该项目为开源项目:地址,并附上Demo https://ask.databend.rs/
编译代码
这一步可以不需要跟着做,只展示流程。
先提前安装好cargo,可以通过brew cargo 或者apt-get install cargo安装。
编译代码:
git clone https://github.com/datafuselabs/askbend
cd askbend
make build
执行成功后会生成在target/release/目录下生成askbend文件。到这一步已经编译完成,但想成功运行,还需要再做一些准备。
数据源初始化
先注册databend国际站(试过注册中文站,中文站不能使用openai提供的接口,问过客服表示是网络问题,所以只能注册国际站)。注册很容易,不像现在国内网站注册还必须输手机和身份证:)。
注册完成后登录,会送200RMB的额度,所以跑askbend测试代码是没问题的。
进入到databend的控制台,选择Worksheets->New Worksheet,然后输入如下SQL并在控制台执行:
CREATE DATABASE askbend;
USE askbend;
-- doc table.
CREATE TABLE doc (path VARCHAR, content VARCHAR, embedding ARRAY(FLOAT32));
-- doc query answer.
CREATE TABLE doc_answer(question VARCHAR, prompt VARCHAR, similar_distances ARRAY(FLOAT32), similar_sections VARCHAR, answer VARCHAR, ts TIMESTAMP);
执行完毕后左侧刷新会出现askbend数据库和2张表doc和doc_answer。
进入到databend控制台的Warehouse标签页选择default的warehouse,右侧选择connect,记录下SQL User、Password、Host3个字段,然后返回程序。
修改程序目录下的配置文件,其位于/conf/askbend.toml。将dsn字段中对应的参数填入刚刚记录的字段。
执行命令对文档内容初始化:
./target/release/askbend -c conf/askbend.toml --rebuild
注意:askbend文档在/data目录下,如果只希望测试程序流程则可以删除大部分文档,只保留个位数文档,提升数据源初始化效率。
如果控制台输出Rebuild done则表示成功执行:

如果出现其他报错,则看看是否是配置文件中dsn字段配置出错。
测试
在askbend目录输入以下代码:
./target/release/askbend -c conf/askbend.toml
开启另外一个Terminal,然后可以分别测试观察返回结果:
curl -X POST -H "Content-Type: application/json" -d '{"query": “how to connect databend?"}' http://localhost:8081/query
curl -X POST -H "Content-Type: application/json" -d '{"query": "what is your name?"}' http://localhost:8081/query
我分别问了如下问题:
- how to connect databend?
- what is your name?
得到的结果是:
{
"result":"Databend can be connected with MySQL Client, ClickHouse HTTP Handler, REST API, MySQL-Compatible Clients, bendsql, Python, Golang, and Node.js. For more information on how to connect with each of these options, please refer to the Databend documentation under the \"Guides\" section."
}
{
"result":"Sorry, I don't know how to help with that."
}
第2个问题没有答案,执行结果符合预期。
执行流程和实现
AskBend的实现大致就是分为2个部分:文档拆分和组合查询。
大致实现思路为:将文档内容分割成合适长度的小节(section),然后调用openai的embdding api计算每个小节的特征向量并存储。当用户提问时,计算提问内容的特征向量,通过余弦求出相似的几个文档小节,组合成Prompt调用openai的completion api获取最终结果。
代码实现大致为:
- 读取并解析指定目录下的所有的markdown文件
- 提取和拆分内容并将其存储至databend数据库中的doc表
- 使用databend提供的
ai_embedding_vector方法,以doc的path和content作为参数,计算出embdding值并存储 - 使用databend提供的
cosine_distance进行余弦计算,找到相似的content - 通过databend提供的
ai_text_completion将检索到的内容串联起来并使用openai继续完成工作 - 输出
completion为markdown格式
在代码执行流程中,分为2部分,首先需要使用askbend --rebuild进行数据源初始化,这一步会分割文档并对分割后的文档内容做一次embdding然后存入数据库中。第2部分则是正常的askbend运行,会开启一个服务端模式,负责接收客户端的request然后返回响应。接下来一个一个分析。
askbend --rebuild实现
由于不懂rust代码,所以这边先从数据源反推代码流程,下图给出了具体的被拆分的01-guides文档和该文档被拆分后的存储内容:
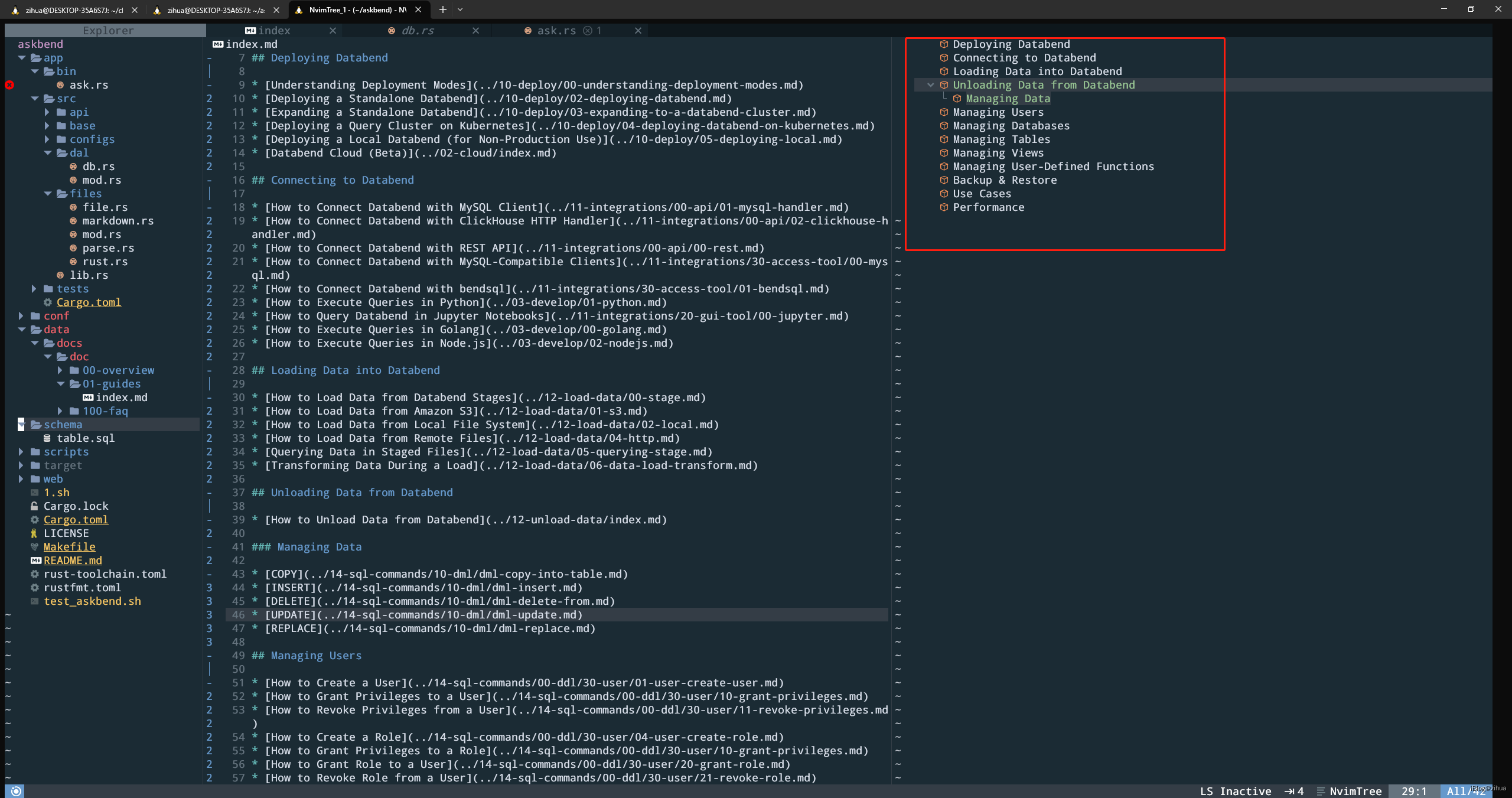
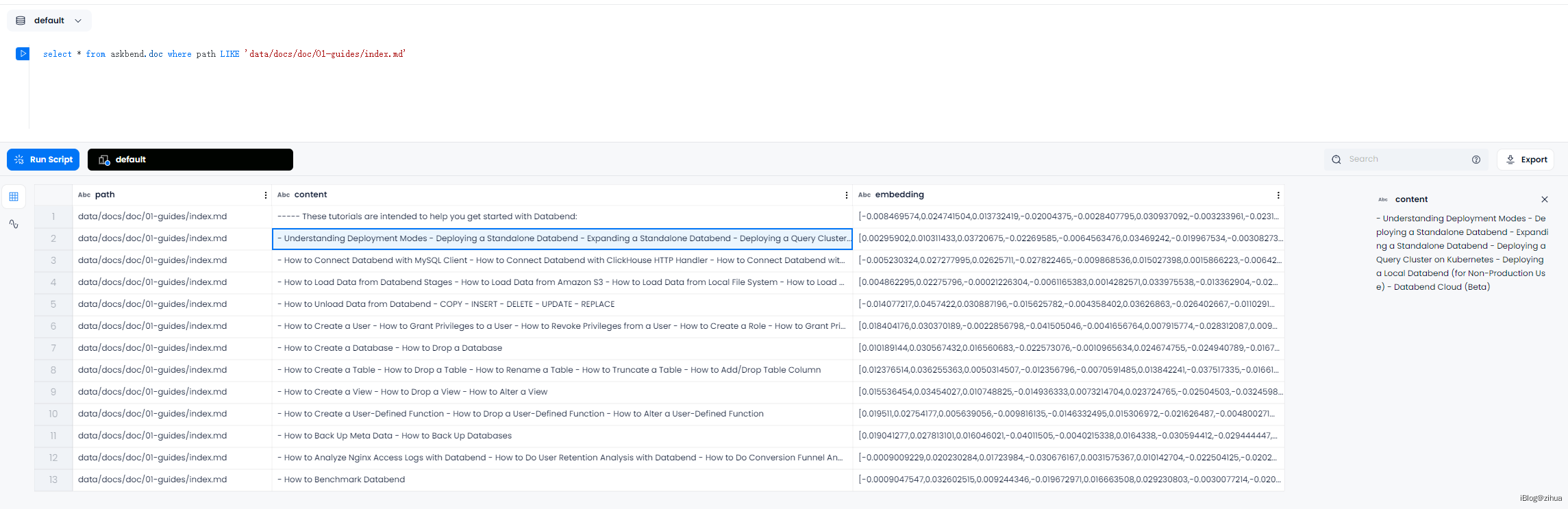
图中可以观察到相同点,如:
01-guides有13个section,拆分后存储的数据有13条01-guides的content字段与该section下的内容完全一致01-guides的content中并没有包含标题信息
其实可以从这些内容中猜测一些东西出来,比如拆分的section对应doc表的content字段;比如第3点就可知道section的标题可能是被拿去提供给embdding计算向量了,这也解释了为什么没有标题相关的存储;
经过分析不难看出--rebuild的实现在askbend/app/bin/ask.rs文件中。由于本人第一次接触rust,所以很多基础细节不太懂,只能从结果和经验推断实现细节,本文最终的mysql knowledge会使用go实现。
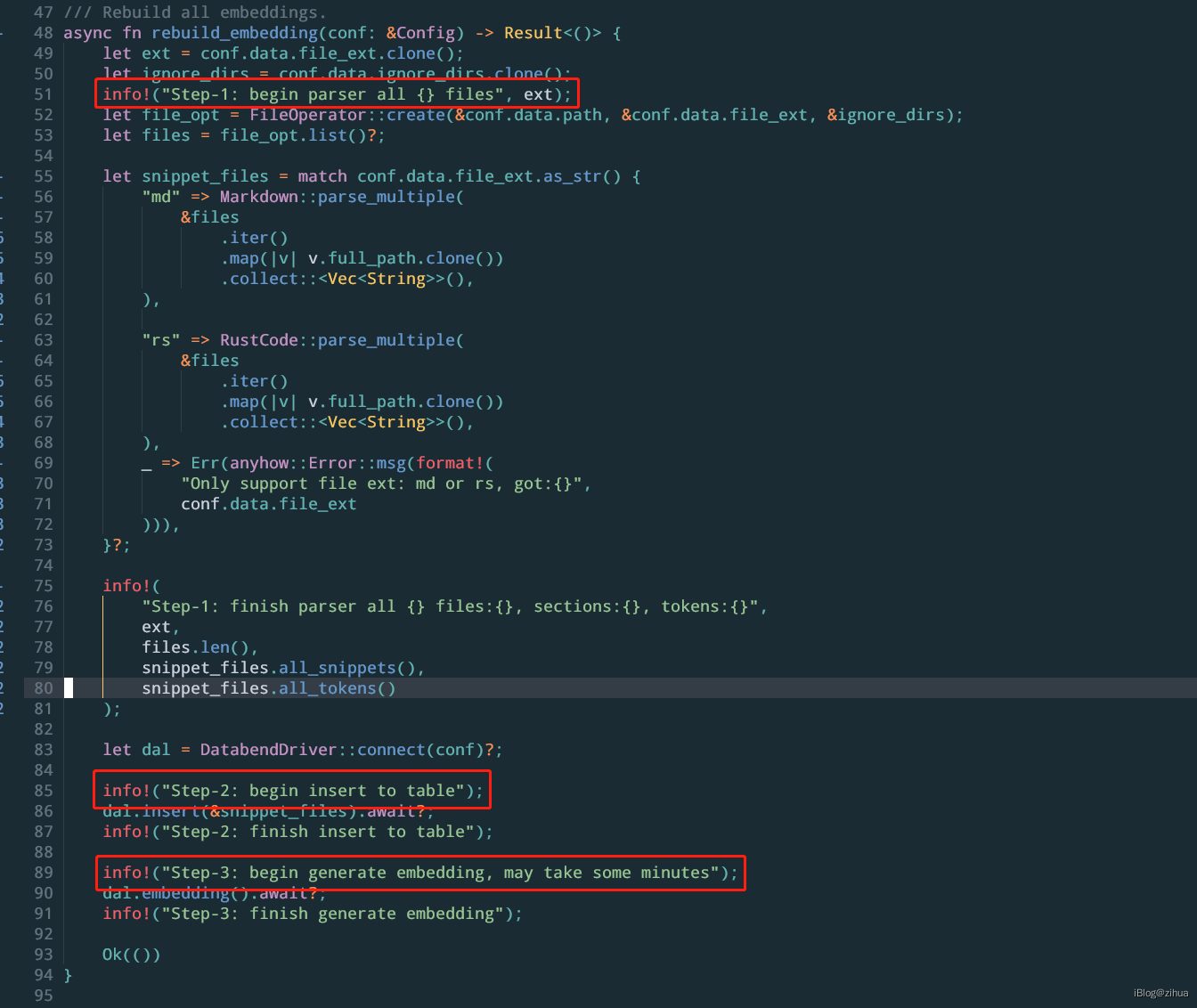
如图可以看出rebuild实现的3步:
- 通过
Markdown::parse_multiple方法解析/data目录下的markdown文件 - 调用
dal.insert() - 调用
dal.embedding()
dal.insert()
dal.insert()的代码位于askbend/app/src/dal/db.rs文件中:
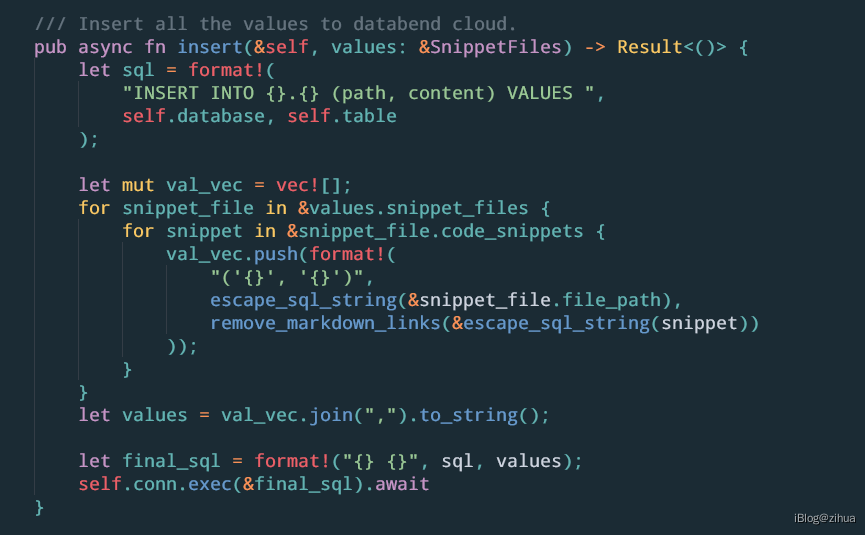
可以提炼出该SQL为:
INSERT INTO {}.{} (path, content) VALUES ('{}', '{}')
其中4个{}均为占位符,前2个分别为数据库名和表名,后2个为第1步拆分的路径和内容。
dal.embdding()
dal.embdding()的代码位于askbend/app/src/dal/db.rs文件中:
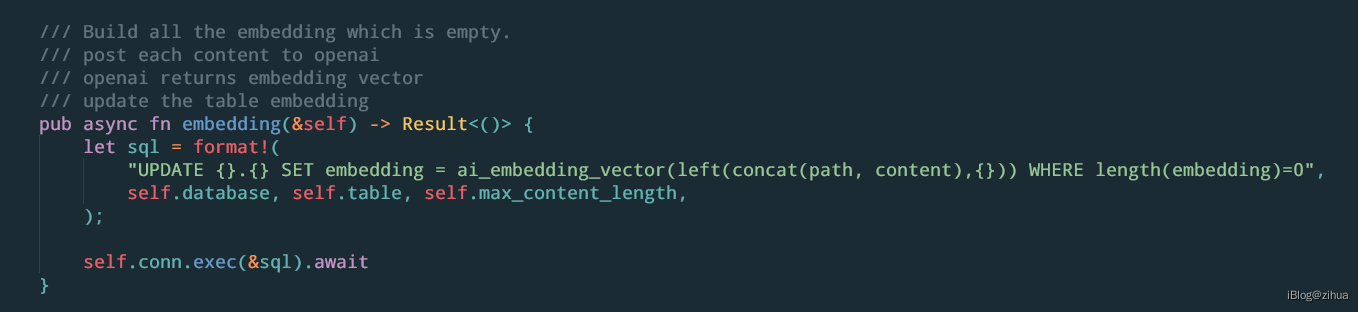
可以提炼出SQL:
UPDATE {}.{} SET embedding = ai_embedding_vector(left(concat(path, content),{})) WHERE length(embedding)=0
其中3个占位符分别是数据库名,表名和最大长度max_content_length。
如图,在初始化DatabendDriver时会对max_content_length做初始化,该参数应该是表示最大分割长度:
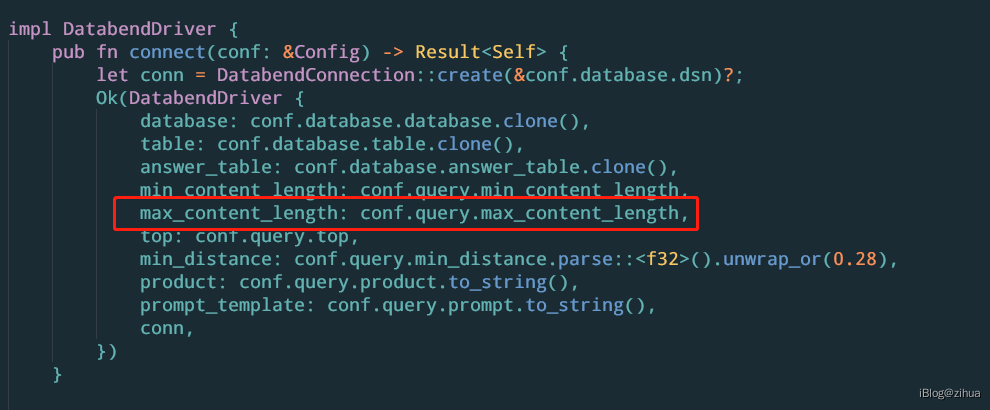
该参数读取的conf.max_content_length默认值为8000

第2步中的update语句并没有在意标题,所以之前的猜测错误,流程是直接把content和path连接起来交给ai_embedding_vector进行运算然后存储向量。
askbend后端实现
在上面小节(AskBend解析#测试)中演示过使用curl模拟post请求获取返回结果,该部分为askbend后端的实现。
入口函数为askbend/app/bin/ask.rs的start_api_server方法:
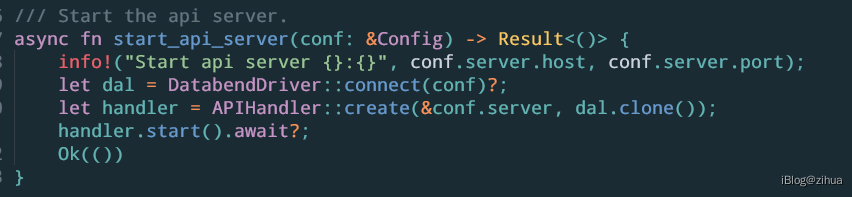
可以看到核心代码分3步:
- DatabendDriver::connect
- APIHandler::create
- handler.start
其中核心代码为第3步,其余2步主要完成初始化工作。
handle.start
start代码如下:
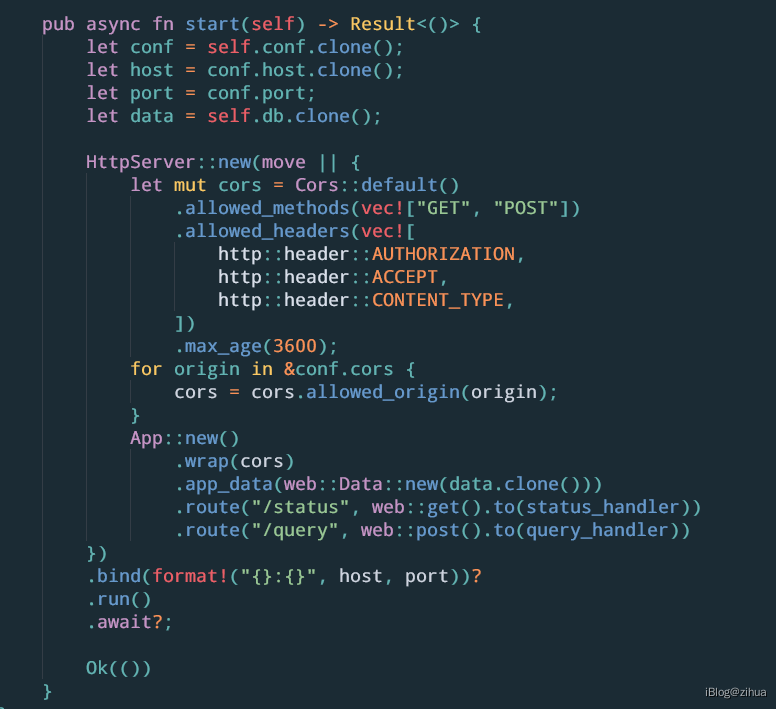
从代码中能推断出,askbend的后端服务映射了2个接口/status和/query,对应的处理程序分别为status_handler和query_handler。
query_handle
这里主要看query_handler的实现:
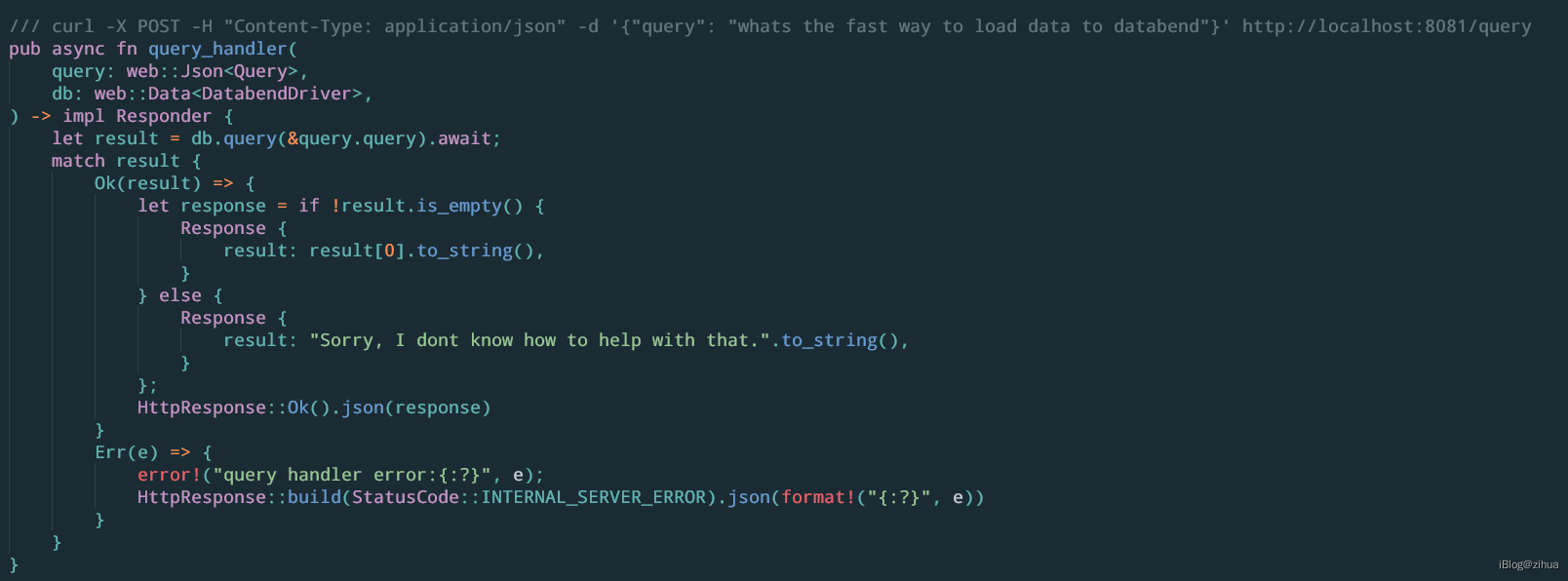
主要通过POST传递过来的参数query去调用了db.query。其中db.query的实现在askbend/app/src/dal/db.rs中。
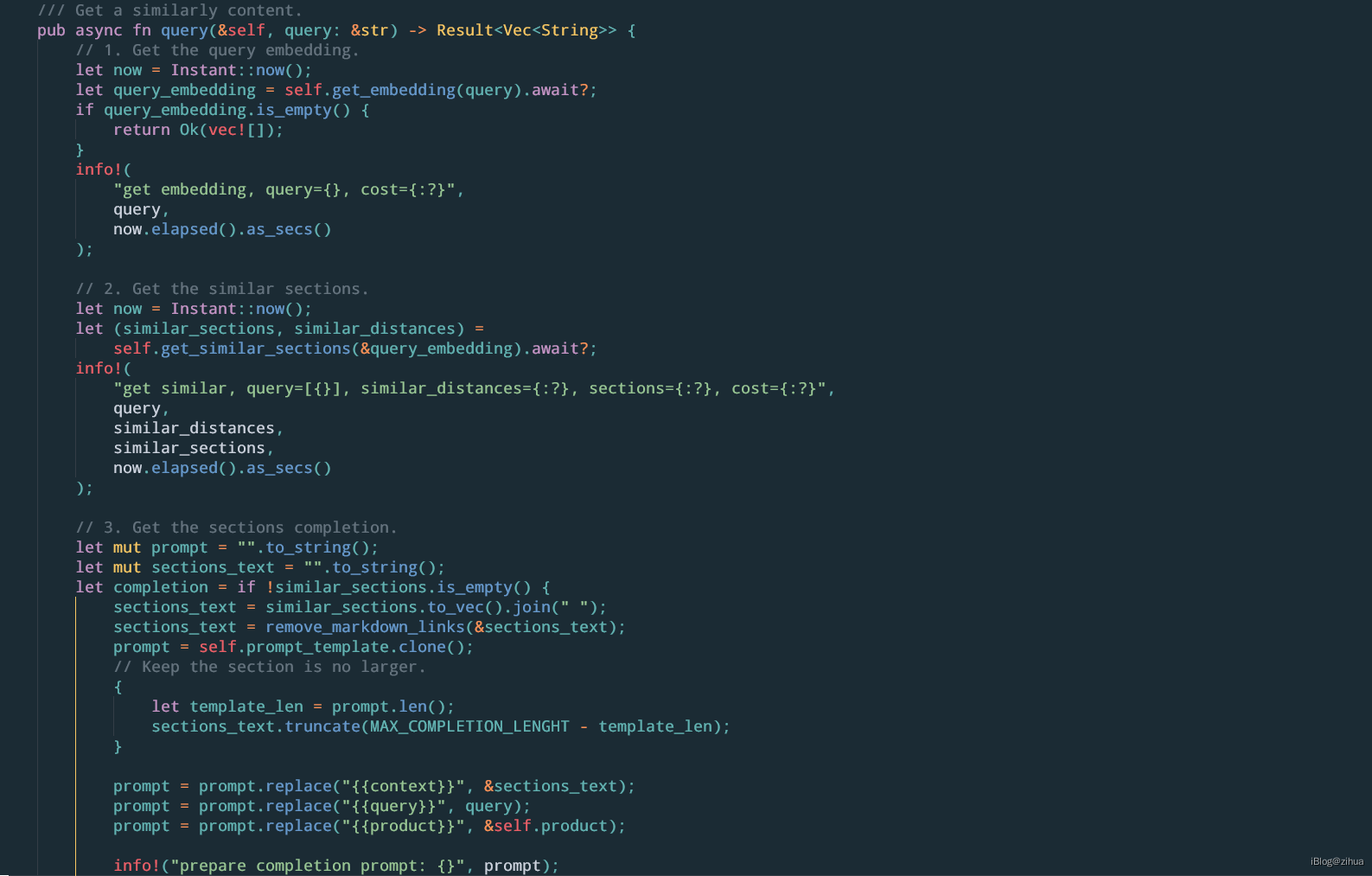

该代码的流程如下:
- 对客户端的参数
query调用get_embdding,对query获取embdding向量 - 对1中返回的embdding结果调用
get_similar_sections,获取库中相似度较高的section - 通过section构造prompt,从prompt_template中获取模板,该模板为
conf/askbend.toml中配置的prompt参数 - 对prompt做处理,首先使用truncate保证每个section不会太大。然后填充模板内的context、query和product字段
- 调用get_completion获得context_completion
- 将(query, prompt, similar_distances, section_text, completion)插入到doc_answer表中
get_embdding
get_similar_sections
get_completion
参考
- https://al-assad.github.io/posts/replicate-askbend-on-postgres/
- https://github.com/datafuselabs/askbend
- https://platform.openai.com/docs/guides/embeddings
- https://platform.openai.com/docs/guides/fine-tuning
- https://zhuanlan.zhihu.com/p/609359047
- https://zhuanlan.zhihu.com/p/609359999
- https://platform.openai.com/docs/api-reference/embeddings/create
- https://en.wikipedia.org/wiki/Cosine_similarity

