start 2020年4月28日00:08:20
引言
主要涉及三个部分:JVM的内存区域、JVM类加载机制和JVM字节码执行引擎
JVM的内存区域
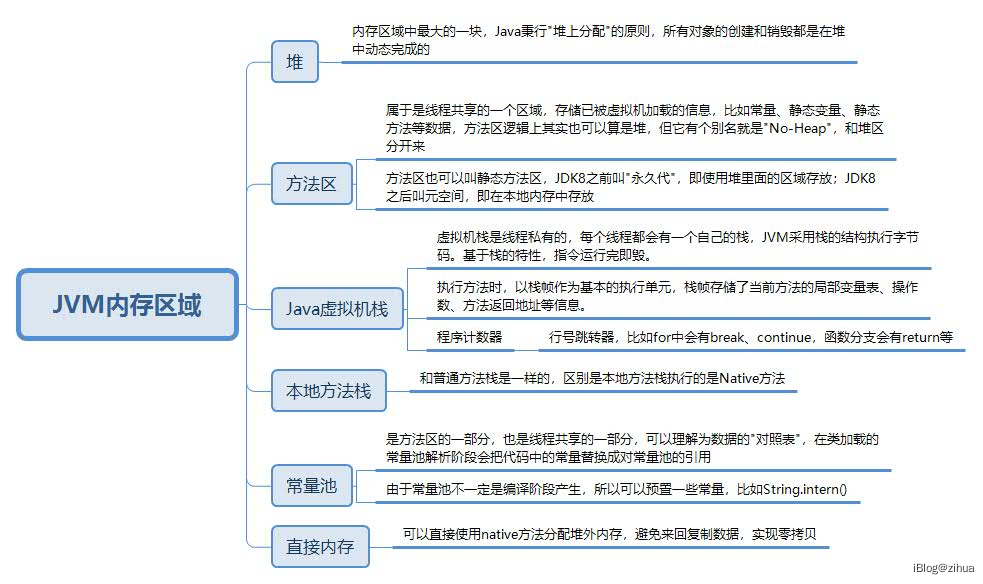
JVM的内存区域简单的可以分为堆区和栈区
详细的可以为堆区、方法区、Java虚拟机栈、程序计数器、本地方法栈
如果更详细的还可以加上运行时常量池和直接内存区域。
java一切皆对象,程序中使用最多的也是对象,秉行着对象皆在堆上分配堆上销毁的原则,所以堆区是最大的一块区域。
方法区逻辑上也是堆的一部分,但有个别名叫做"No-Heap",与堆区分开,在类加载准备阶段时,会将类中的静态方法存入方法区,当然一些类常量也会落入方法区里面,JDK8之前的方法区是"永久代",永久代也是堆的一部分;JDK8之后存在于"元空间(meta space)",元空间是内存中的一片区域。
由于Java字节码执行结构是栈的方式而不是寄存器的方式,所以字节码指令的执行、方法的调用,都会将需要执行的过程放入虚拟机栈中。当调用一个方法时,会将方法的栈帧入栈。栈帧是一个结构,里面维护了一个方法的局部变量表、当前执行指令的程序计数器、方法的返回值地址等信息,也就是为什么不同方法的局部变量不冲突的原因,因为栈帧维护了局部变量表。JVM为每一个线程都会创建自己的虚拟机栈,虚拟机栈槽0的位置指向了this。所以虚拟机栈是线程独享区域。
本地方法栈和虚拟机栈是很类似的,不同点是虚拟机栈入栈的是普通方法的栈帧,本地方法栈入栈的是native方法。
常量池就相当于一个资源对照表,这其实也可以看做实现资源复用的一种缓存手段。
直接内存是分配在堆外的内存,由于JVM本身也只是一个运行在OS端的用户程序,如果需要从内核空间拷贝数据,那么会经历很多次IO才能成功的将数据拷贝至用户空间,中间的代价很大,直接内存可以减小这个代价。
总的来说,线程共享区域有堆区、方法区、常量池,线程私有区域有虚拟机栈、本地方法栈。
JVM类加载机制
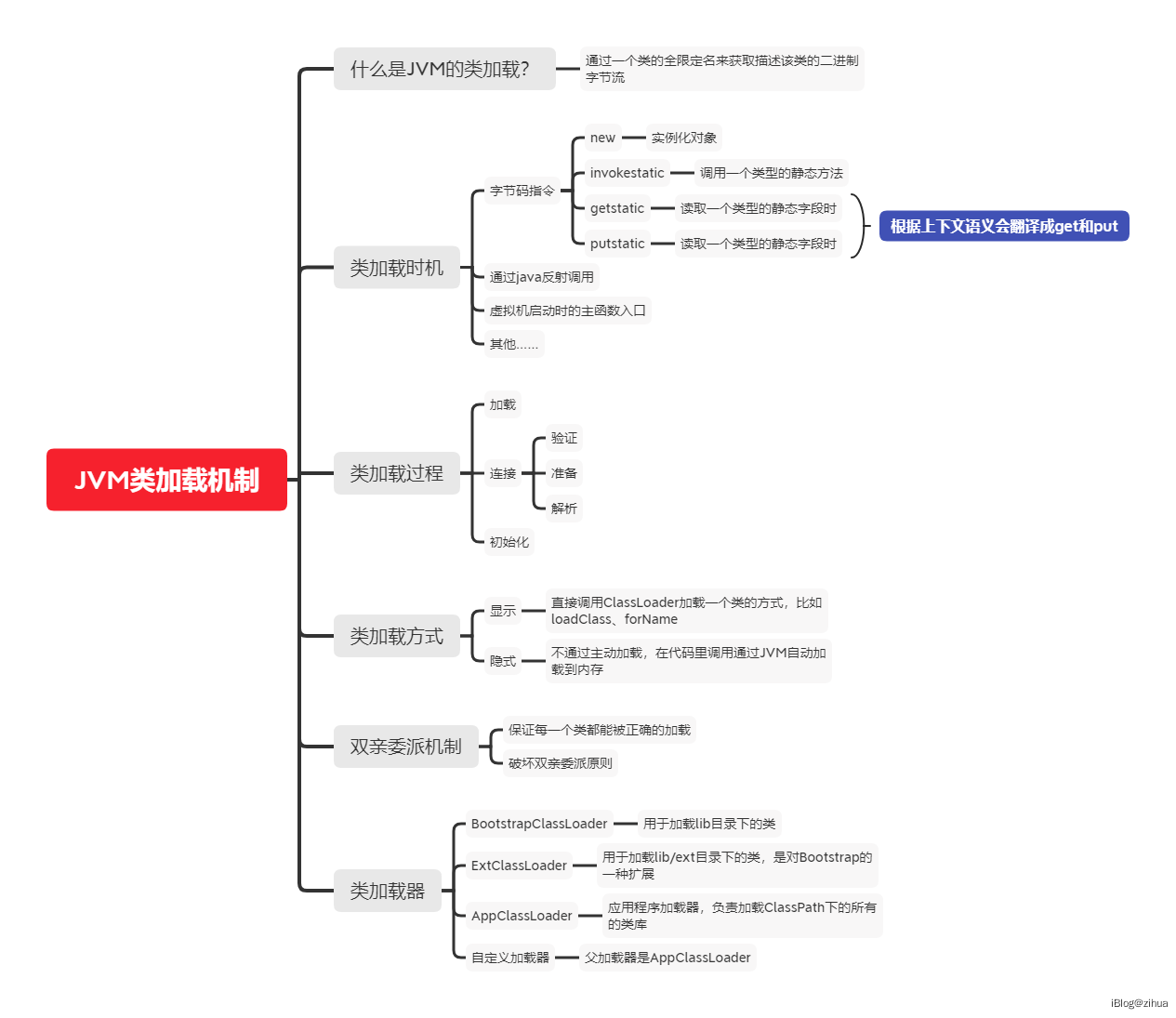
JVM的类加载机制简单点说就是通过一个类的全限定名加载这个类的实例到运行时的数据空间中。
触发类加载的场景有很多,比如执行了部分字节码指令,比如new、getstatic、invokestatic对应的场景就是创建一个对象或者使用一个类静态方法或字段;比如通过反射去调用一个方法也会触发类加载;虚拟机执行会通过一个主类,也就是main函数所在的那个类,会触发这个类的类加载。还有很多情况。。。
类加载的方式分为显示和隐式,显示指的是直接通过类加载器去加载一个类,比如forName,loadClass等说;隐式指的是不主动加载,代码里通过JVM加载。
类加载的过程分为加载阶段、连接阶段和初始化阶段。
加载阶段JVM需要做的是会从类的全限定名读取这个文件的二进制字节码流,将字节流中的数据转换成运行时的数据,在内存中创建这个类所代表的的java.lang.Class对象作为该类其他数据的入口。所谓的全限定名,可以简单理解为定位这个文件的绝对路径。Java虚拟机规范中在加载阶段的规定并不具体,所以留个开发者的空间非常大,于是便有了很多种加载情况:比如通过压缩文件读取字节码,经常见到的是jar包和war包;从网络获取字节码,比如RMI调用;运行时动态计算,比如动态代理;从加密文件中读取字节码,这可能需要定制闭源虚拟机来实现。这一阶段对开发者来说可控性最强,而且java也支持程序员去使用自定义的类加载器处理。
然后就是连接阶段,连接阶段分为三个步骤:校验、准备和解析。校验很好理解,就是检查你的字节码流是否符合规范,当然这一步可能会问,加载阶段不是已经创建好类了么,那校验怎么在创建之后呢?别急,加载阶段和连接阶段并非是串行的,他们可能是交叉执行的,加载阶段读取字节码流后才会触发文件校验。准备阶段会将类中的变量分配内存并初始化,比如静态变量(static)、常量,这些静态数据在方法区分配。解析步骤会将常量池内的符号引用替换成直接引用,符号是一种字面量,比如一串字符串也可以是符号引用,一个数字也可以是,前面提到过了,常量池就是一种对照表,通过这个对照表中的"key"去找到这个符号字面量,这一步可以理解为将代码中的value替换成key的过程,因为key是唯一的,value并不唯一,常量池可以算是一种JVM实现资源复用的缓存池。
初始化阶段是最后一个动作,前面虚拟机为我们把所有的准备工作完成了,数据也都合理的分配到不同的区域,这个时候让这些数据指向他们的引用就完成了类加载过程。
类在加载阶段是通过类加载器读取字节码流,类加载器是分层级的,最顶层的是BootstrapClassLoader,主要加载lib目录下的类;然后就是ExtClassLoader,加载lib/ext目录下的扩展类;然后就是AppClassLoader,应用程序加载器,加载用户类;然后就是自定义类加载器,这个是最底层。
关于类加载器会有一个双亲委派机制,所谓的双亲委派,我记得是翻译上的问题,parent其实有一层"长辈"的含义。简单的说,双亲委派就是类加载器在加载一个类时,优先委派给父加载器加载这个类,每一个层级的加载器都是如此,只有当父加载器无法完成加载请求时,子加载器才会尝试加载。这样做的好处就是类会有一个优先级,比如Object、Class这种存在于lib中的类,会让顶层的Bootstrap加载,因此在各个加载器环境中都能保证加载到的是同一个类。
(双亲委派原则也是可以被破坏的,只要破坏这种层级结构就行)
JVM字节码执行引擎
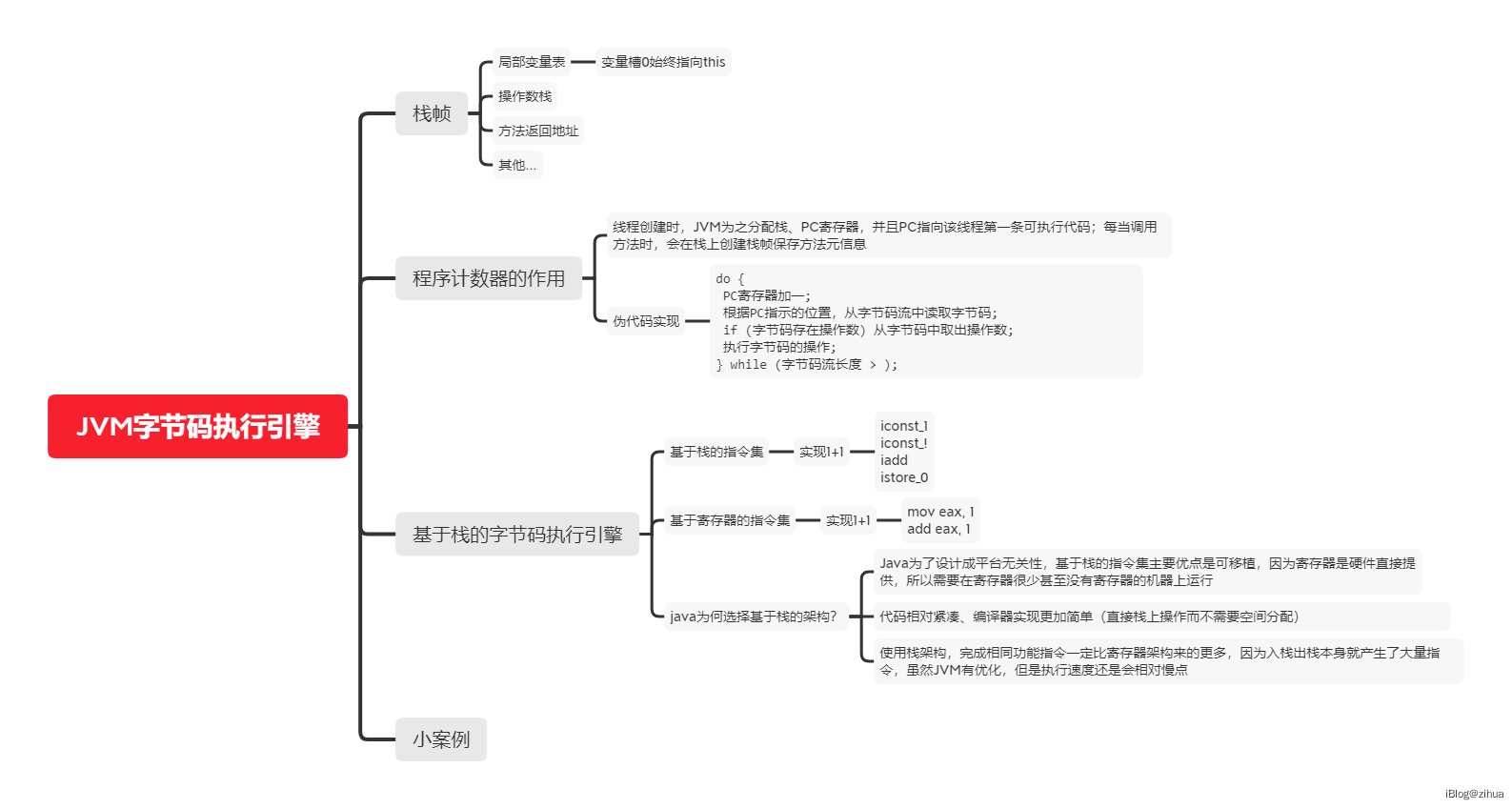
我们可以模拟一下jvm是如何执行一个字节码的。
首先介绍一下栈帧,前面介绍Java虚拟机栈的时候也提到过栈帧的概念,栈帧是方法执行背后数据单元,里面有局部变量表、操作数栈、程序计数器、方法出口地址等记录。每执行一个方法都会创建一个栈帧push到虚拟机栈中,所有的栈帧执行完毕,虚拟机栈也就会自动销毁,程序也就结束了。
线程创建时,JVM也会为之分配局部变量表、程序计数器等,我们可以简单模拟一下线程执行字节码的过程:
do {
程序计数器 + 1;
根据程序计数器的位置,从字节码流中读取字节码;
if (字节码中是否有操作数或引用?) 取出操作数(压栈);
执行指令;
} while (字节码流长度 > 0);
前面介绍虚拟机栈的时候提到了,java为了实现跨平台所以指令集采用栈的执行引擎,为什么基于栈而不基于寄存器呢?
Java为了实现跨平台牺牲了很多,因为寄存器是硬件实现的,比如A有32位寄存器,B有256位寄存器,如果我基于寄存器的指令结构,那么就需要适配AB两种设备的执行引擎。基于栈的结构可以做到的就是可以在很少甚至没有寄存器的情况下也能正确的解析执行,但使用栈的结构速度肯定会慢一点,举个例子:
同样是实现1+1,基于栈的实现:
iconst_1 // 将常量1压栈
iconst_1 // 将常量1压栈
iadd // 对栈顶的两个数相加,结果入栈
istore_0 // 将栈顶的值放到局部变量表的槽0中
基于寄存器的实现:
mov eax, 1 // 寄存器1置为1
add eax, 1 // 寄存器eax的值加1
同样是一行代码,两种架构执行的代码量完全不同,但也需要注意的是,栈本身的入栈和出栈也是指令,也是有执行周期的,所以这个差距会更大,虽然JVM对此有过优化,但是治标不治本。
接下来我放一个小案例,模拟栈帧的执行过程,很简单的例子:
public class Main {
public static int calc() {
int a = 100;
int b = 200;
int c = 300;
return (a + b) * c;
}
public static void main(String[] args) {
int i = calc();
System.out.println(i);
}
}
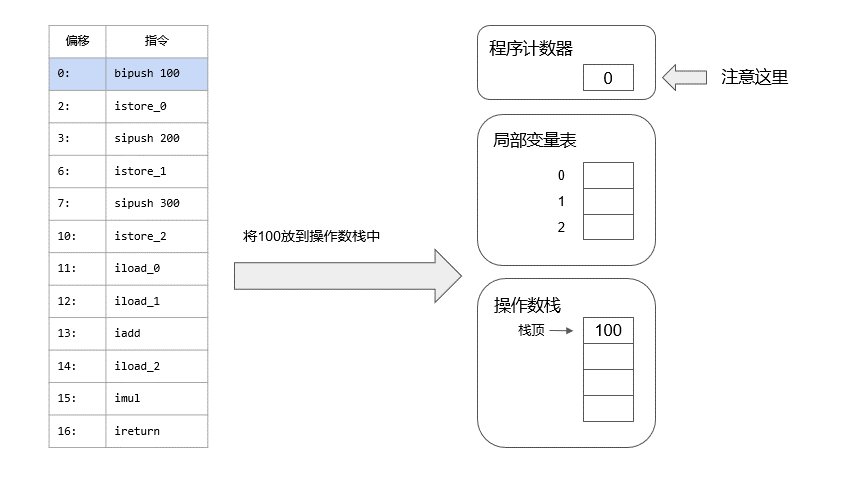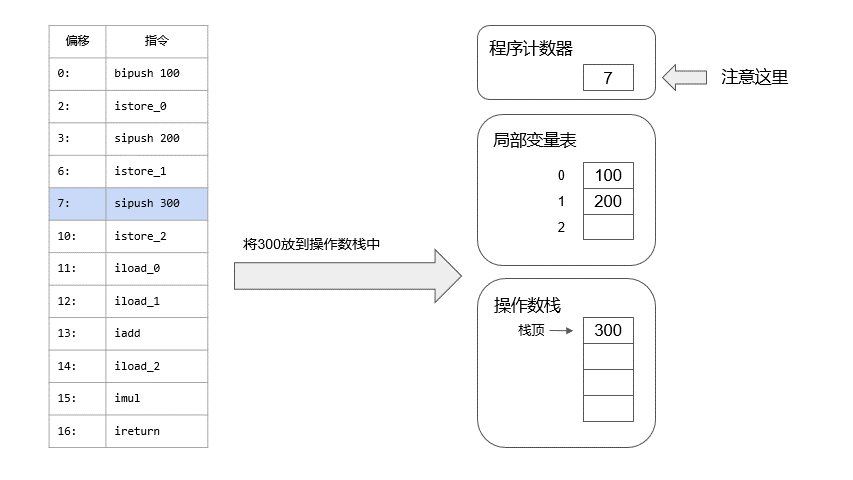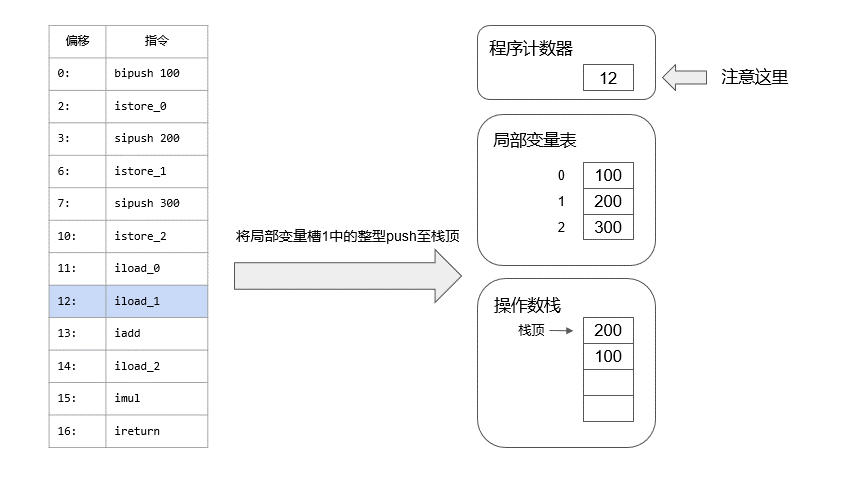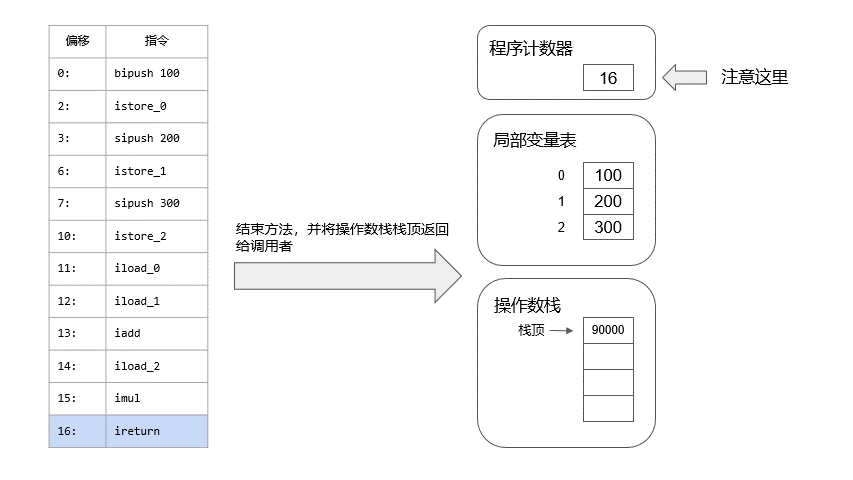
calc方法编译后的字节码如下:
0: bipush 100
2: istore_0
3: sipush 200
6: istore_1
7: sipush 300
10: istore_2
11: iload_0
12: iload_1
13: iadd
14: iload_2
15: imul
16: ireturn
我把信息分离出来,这样看起来会清晰很多,我们可以先模拟一下calc是如何被执行的,我做了一个动画:
接下来看main函数中是如何调用calc方法的,非常简单:
0: invokestatic #2
3: istore_1
4: getstatic #3
7: iload_1
8: invokevirtual #4
11: return
下面还有一个LocalVariableTable(局部变量表):
| Start | Length | Slot | Name | Signature |
|---|---|---|---|---|
| 0 | 12 | 0 | args | [Ljava/lang/String; |
| 4 | 8 | 1 | i | I |
常量池的数据比较多,我不放在此处,有兴趣的可以自己查看。
invokestatic调用了常量池中#2的引用,#2其实也就是calc(),此处调用calc然后将返回值入栈,istore_1将calc的结果放至局部变量槽1中,从表中也可以看到这个槽1就是i,剩下的代码其实就是获取系统的标准输出,读取变量槽1,然后调用out方法输出。
整个过程完成。
end 2020年4月29日06:17:50
参考
- [1] 周志明.《深入理解Java虚拟机-JVM高级特征与最佳实践》第三版

